语音增强使用说明¶
语音增强算法主要用于噪声环境下,抑制噪声和干扰,增强目标语音。本文档主要介绍其适用场景以及如何开启该功能。
1. SDK中DOA和语音增强算法的默认配置和对应硬件板¶
CI110系列芯片纯离线SDK不支持语音增强算法,算法SDK和离在线SDK中语音增强算法默认为打开状态。使用语音增强算法必须采用双麦克风硬件方案,可用启英泰伦提供的CIB03ST01J-WL21等离在线模块板或用户自行开发的双麦克风模块板,具体硬件选型可咨询启英泰伦技术支持人员。
如果用户需要测试算法效果,还需准备录音板(该录音板可在启英泰伦官网中的启英商城中购买)。用该录音板可以直接观察并分析算法效果以便于调试。录音板的使用方法请参考语音AI平台中的《CI110X模组底噪录音分析》文档。
2. 应用场景¶
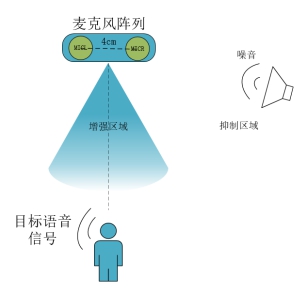
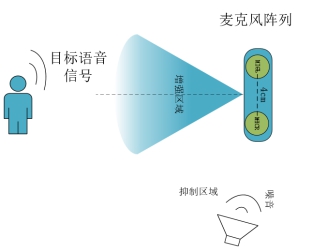
语音增强算法适应的典型应用环境示意图如下图所示,图a、b中,麦克风阵列为线性双麦阵列,推荐麦间距为4cm,其结构方向与实际应用环境中的噪音源方向及目标人声方向相适应。目标人声在语音增强范围内,噪音信号在抑制范围内。语音增强算法可以起到在嘈杂环境中抑制噪声与增强目标人声的作用,开启后可以提升语音识别的效果。DOA算法可以获取目标人声方位角度,如果需要获取目标人声位置,请打开DOA算法,具体使用详见《DOA使用说明》。
 {: .center .img-fluid tag=1 }
{: .center .img-fluid tag=1 }
图 (a) 麦克风阵列横向结构噪声和目标信号示意图
 {: .center .img-fluid tag=1 }
{: .center .img-fluid tag=1 }
图(b) 麦克风阵列竖向结构噪声和目标信号示意图
3. SDK开发示例的选择¶
离在线SDK:
- CI110X_SDK_Combine_Cloud/sample/internal/sample_media
sample_media是针对离在线方案场景的应用。该示例中算法功能配置方法与下文中算法SDK的sample中所提到的配置方法一致,因此不单独为其进行介绍。
算法SDK:
以下提供了几种典型的sample应用示例供用户使用,并对相关配置进行了简要说明
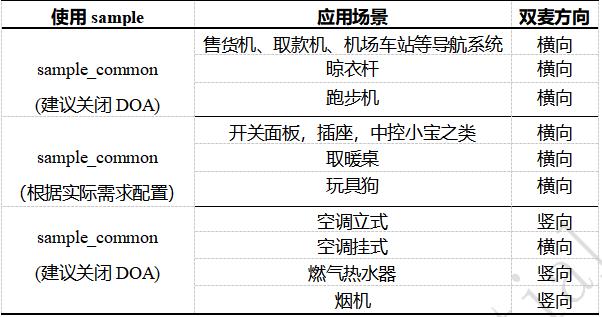
1) 通用场景
一般场景下,如说话人位置、噪声方位不固定时,用户可以选择sample_common工程,并配置是否开启或者关闭各算法模块,如DOA估计算法模块、denoise算法模块、语音增强算法模块(ci_bfA.a或ci_bfB.a)、回声消除算法模块、降混响算法模块等,以满足产品需求,语音增强算法模块使用请参考本文第4.1节内容。
2) 烟机应用场景
该应用场景中,目标方向位于双麦的正前方,而噪声方向位于双麦的一侧,用户可以选择sample_common工程。应用中建议关闭DOA估计算法模块,开启语音增强算法模块(使用ci_bfA.a)或者开启降混响和denoise算法模块及使用433模型。并根据实际噪声方向和目标人声方向,预先设置目标人声角度,使用方法请参考本文第4.1节内容。
3) 跑步机应用场景
该应用场景中,目标方向位于双麦的正前方,而噪声方向位于双麦的一侧,用户可以选择sample_common工程。应用中建议关闭DOA估计算法模块,开启语音增强算法模块(ci_bfA.a)及使用144模型。并根据实际噪声方向和目标人声方向,预先设置目标人声角度,使用方法请参考本文第4.1节内容。
实际应用参考
以下推荐情况仅供参考,具体应用需与实际场景相结合。可根据实际声源和噪音源方向的判断,选择是否开启DOA估计算法模块。若噪声源为产品自身运作产生的噪声,如烟机噪声、跑步机噪声等,建议关闭DOA算法模块,对应关系如下表a所示。mic方向参考上图(a、b)所示。
 {: .center .img-fluid tag=1 }
{: .center .img-fluid tag=1 }
4. sample_common工程使用说明¶
4.1 语音增强算法的使用¶
步骤一:开启语音增强算法
在文件sample\internal\sample_*\src\user_config.h开启相关的宏以开启语音增强算法。
应用一:开启AEC功能的应用,需要使用外部codec
#define AUDIO_CAPTURE_USE_MULTI_CODEC 1
#define USE_TWO_MIC_ BEAMFORMING 1 //1为开启,0为关闭, 默认配置为开启
应用二:关闭AEC功能的应用,无需外部codec
#define AUDIO_CAPTURE_USE_MULTI_CODEC 0
#define USE_TWO_MIC_ BEAMFORMING 1//1为开启,0为关闭, 默认配置为开启
步骤二:语音增强算法库的选择及适用范围
随着SDK版本的更新升级,算法SDK中A、B库的适用范围也有所变化,现针对不同版本的SDK,对A、B库的适用范围做一个简要说明。
-
CI110X_SDK_ALG_Application_V1.5.9以下版本中,有3个不同的工程:通用工程(sample_common)、自学习工程(sample_cwsl)以及烟机工程(sample_range_hood)。其中通用工程使用ci_bfA库,烟机工程中使用ci_bfB库,这两个bf库算法原理相同,只是为适应不同的使用场景而调试的参数不同。自学习工程在此不做描述。
-
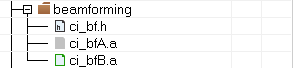
CI110X_SDK_ALG_Application_V1.5.9及其以上版本中,删除了烟机工程,保留了通用工程和自学习工程,且在通用工程中,同时存在ci_bfA、ci_bfB两个算法库。这两个算法库原理不同,ci_bfA库保留了之前SDK版本中的ci_bfA库,ci_bfB库为新的算法库。在SDK1.5.9及其以上版本中默认开启ci_bfB库,关闭ci_bfA库,如下图。现将SDK1.5.9及其以上版本的ci_bfA、ci_bfB库的使用做简要说明:
 {: .center .img-fluid tag=1 }
{: .center .img-fluid tag=1 }
①. A库建议在已知目标声源角度时使用,如默认90°。若使用A库且需要调整mic间矩及重新设置初始角度,请按如下操作:
在sdk\compoents\audio_in_manage\alg_preprocess.c文件中算法初始化过程中设置mic间距、初始角度和频点参数:
#define MIC_DISTANCE MIC_DISTANCE_40MM //默认间距40mm
bf = ci_bf_create( MIC_DISTANCE ); //设置间距函数
#define SET_ANGLE SET_ANGLE_90_DEGREE //默认角度90度
bf = ci_bf_set_direction( bf, SET_ANGLE ); //设置角度函数
#define SET_FREBIN SET_FREBIN_COMMMON //默认频点为215
bf = ci_bf_set_para( bf, SET_FREBIN ); //设置频点函数
注意
可选间距为:
30mm: MIC_DISTANCE_30MM
40mm: MIC _DISTANCE_40MM
50mm: MIC_DISTANCE_50MM
80mm: MIC _DISTANCE_80MM
120mm:MIC_DISTANCE_120MM
除默认角度90度外可选初始角度有:
45°:SET_ANGLE_45_DEGREE
135°:SET_ANGLE_135_DEGREE
在开启DOA估计算法情况下,无需调用ci_bf_set_direction( bf, SET_ANGLE )函数。在关闭DOA估计算法的应用场景中,语音增强算法默认启用目标方向为90度角,若根据实际应用环境需更改目标方向角度,应在初始化函数ci_bf_creat(MIC_DIATANCE)后调用ci_bf_set_direction( bf, SET_ANGLE )接口。
SET_FREBIN_COMMON可根据不同应用场景设置不同参数且在需要修改频点参数时调用;
②. B库建议在噪声较低环境下(65dB以下)使用,且请关闭DOA使用功能,在混响较重的环境下,建议打开降混响功能。无需设置初始目标声源角度和mic间距。
SDK1.5.9以下版本ci_bfA、ci_bfB的使用均可参考SDK1.5.9及其以上版本中的ci_bfA的使用方法。
5. 语音数据通过IIS输出¶
5.1 调试语音输出宏配置¶
CI110X_SDK_ALG_Application\components\voice_upload_manage voice_upload_manage.h中。
//语音数据通过IIS输出调试功能开启
#define VOICE_UPLOAD_IIS_SHOW_DEBUG (1) //0为关闭,1为开启
5.2 数据传输存在3种工作模式¶
模式一:WITH_WAKEUP_WORD_MODEL,唤醒词和命令词同时上传,一次唤醒一次上传。
模式二:WITHOUT_WAKEUP_WORD_MODEL ,只上传命令词,一次唤醒一次上传。
模式三:VAD_REPEATTED_MODEL ,唤醒时间段内,根据vad上传音频,多次上传。
/*配置数据上传模式 ,默认为WITH_WAKEUP_WORD_MODEL*/
#define UPLOAD_VOICE_DATA_MODEL (WITH_WAKEUP_WORD_MODEL)
6 效果确认与调试¶
6.1 调试输出¶
硬件配置:
为了更直观的观察算法的效果,需要借助录音板对语音数据进行分析。录音板的使用教程请参考《CI110X模块板录音分析》
软件配置:
在components\audio_in_manage\alg_preprocess.c中,alg_preprocess_two_ch函数或alg_preprocess_four_ch_single_aec函数中调用
audio_pre_rslt_write_data( (int16_t*)dst, (int16_t*)micl )为IIS输出的数据内容,开启后,录音板才可以从iis录制到声音;
audio_pre_rslt_write_data函数中第一个参数为IIS输出的右声道的数据,第二个参数为IIS输出的左声道的数据,可以填写以下参数:
dst:输出算法处理结果的数据 Ref:输出原始获取到的参考声音
Micl:输出micL获取到的原始声音 MicR:输出micR获取到的原始声音
当设置为:audio_pre_rslt_write_data( (int16_t*)dst, (int16_t*)micl )时,意思为右声道输出算法处理后的结果,左声道为原始的micL的数据,
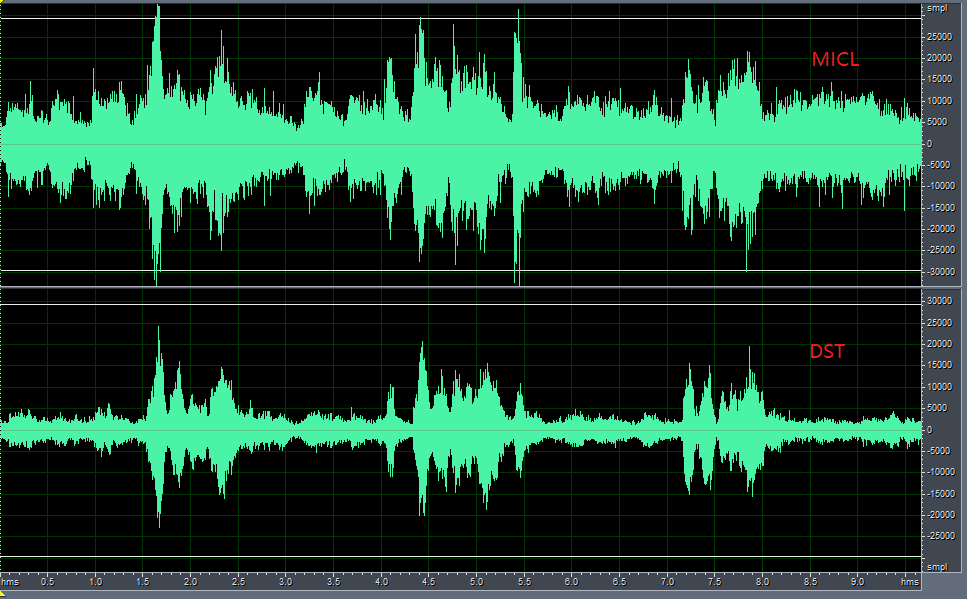
查看语音增强算法功能的效果如下图示,处理后有明显的抑制(目标人声位于mic中间90度,噪音源为音乐噪声,位于0度角位置),说明算法工作正常,以下算法效果使用CI110X_SDK_ALG_Application_V1.5.9版本调试;
A库语音增强后的波形图
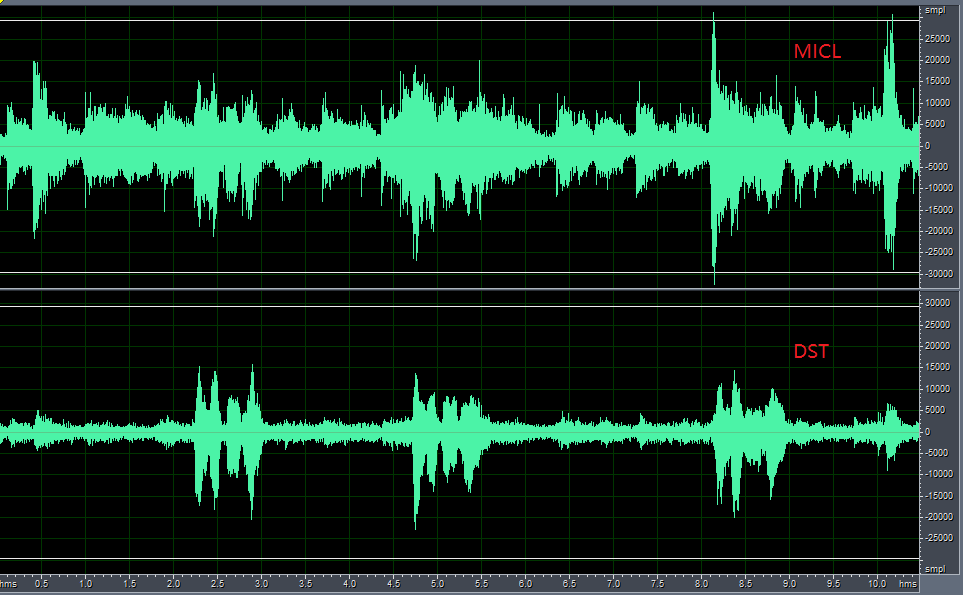
B库语音增强后的波形图