算法SDK开发流程
CI130X 算法SDK 说明文档
1. 概述¶
CI130X_SDK_ALG_PRO_2.3.18版本主要包含了以下算法功能:
| 算法名称 | 算法说明 |
|---|---|
| ASR | 单麦语音识别,固定词条或者自然说 |
| VPR | 基于特定人的声纹识别 |
| WMAN_VPR | 男女声纹检测功能 |
| SED_CRY | 哭声检测功能 |
| SED_SNORE | 鼾声检测功能 |
| DENOISE_NN | 基于识别的深度降噪功能 |
| DOA | 双麦声源定位功能 |
| CWSL | 自学习功能 |
| DERVERB | 双麦降混响 |
| AEC | 回声消除 |
| CWSL_AEC | 自学习加回声消除 |
| TTS | 文本转语音(只支持中文、数字、字母, 不支持英文) |
| BF | 双麦语音增强 |
| AI_DOA_AEC | 双麦声源定位加回声消除(需外挂codec-推荐7243e) |
| DEREVERB_AEC | 双麦降混响加回声消除(需外挂codec) |
| BF_AEC | 双麦语音增强加回声消除(需外挂codec) |
| PWK | 声音能量值值计算,区分目标声音距离 |
| ALC | 自动增益控制 |
注意
- 使用声纹注册、男女声纹检测、哭声鼾声检测、深度降噪、声源定位、语音合成、双麦语音增强算法时,在firmware\dnn文件中需搭配该算法的前端算法模型使用。
- 声纹注册、男女声纹检测、哭声鼾声检测、语音合成算法: 需要购买license,未烧录量产密码,固件每五分钟(TTS算法10秒)会复位一次,如有量产需求,请联系启英泰伦商务。
算法功能组合:
| 开启算法 | 说明 |
|---|---|
| ASR | 只开识别,不开其他算法 |
| ASR+声纹 | 同时开启识别加VPR声纹注册功能 |
| ASR+男女声纹 | 同时开启识别加WMAN_VPR男女声纹识别功能 |
| ASR+深度降噪 | 同时开启识别加DENOISE_NN深度降噪功能 |
| ASR+声源定位 | 同时开启识别加DOA声源定位功能 |
| ASR+自学习 | 同时开启识别加CWSL自学习功能 |
| ASR+降混响 | 同时开启识别加DERVERB降混响功能 |
| ASR+回声消除 | 同时开启识别加AEC回声消除功能 |
| ASR+自学习加回声消除 | 同时开启识别加自学习加回声消除 |
| ASR+双麦语音增强 | 同时开启识别加双麦语音增强 |
| ASR+声源定位加回声消除 | 同时开启识别加声源定位加回声消除 |
| ASR+降混响加回声消除 | 同时开启识别加降混响加回声消除 |
| ASR+双麦语音增强加回声消除 | 同时开启识别加双麦语音增强加回声消除 |
| 语音合成 | TTS语音合成不支持识别 |
| 哭声检测 | SED_CRY哭声检测不支持识别和其他算法功能 |
| 鼾声检测 | SED_SNORE鼾声检测不支持识别和其他算法功能 |
注意
除了上表算法组合功能,不支持其他组合,请勿随意组合算法功能,否则会出现sdk编译异常或者运行故障。
模型ID定义:
开启算法功能需使用不同的前端算法模型,各个算法模型对应ID如下表:
| 模型ID | 模型类型 |
|---|---|
| 60001 | 声纹识别模型 |
| 60002 | 哭声检测模型 |
| 60003 | NN深度降噪模型 |
| 60004 | DOA声源定位模型 |
| 60005 | 鼾声检测模型 |
| 60008 | 男女声纹检测模型 |
| 60009 | TTS语音合成模型 |
| 60010 | TTS语音合成模型 |
2. 算法SDK使用说明¶
以声纹注册算法为例,说明开启对应算法功能需要的步骤。
开启算法:
在projects\offline_asr_alg_pro_sample\project_file\makefile文件中对CI_ALG_TYPE进行修改,CI_ALG_TYPE := $(USE_VPR),修改makefile文件后,请clean清除后再进行编译。
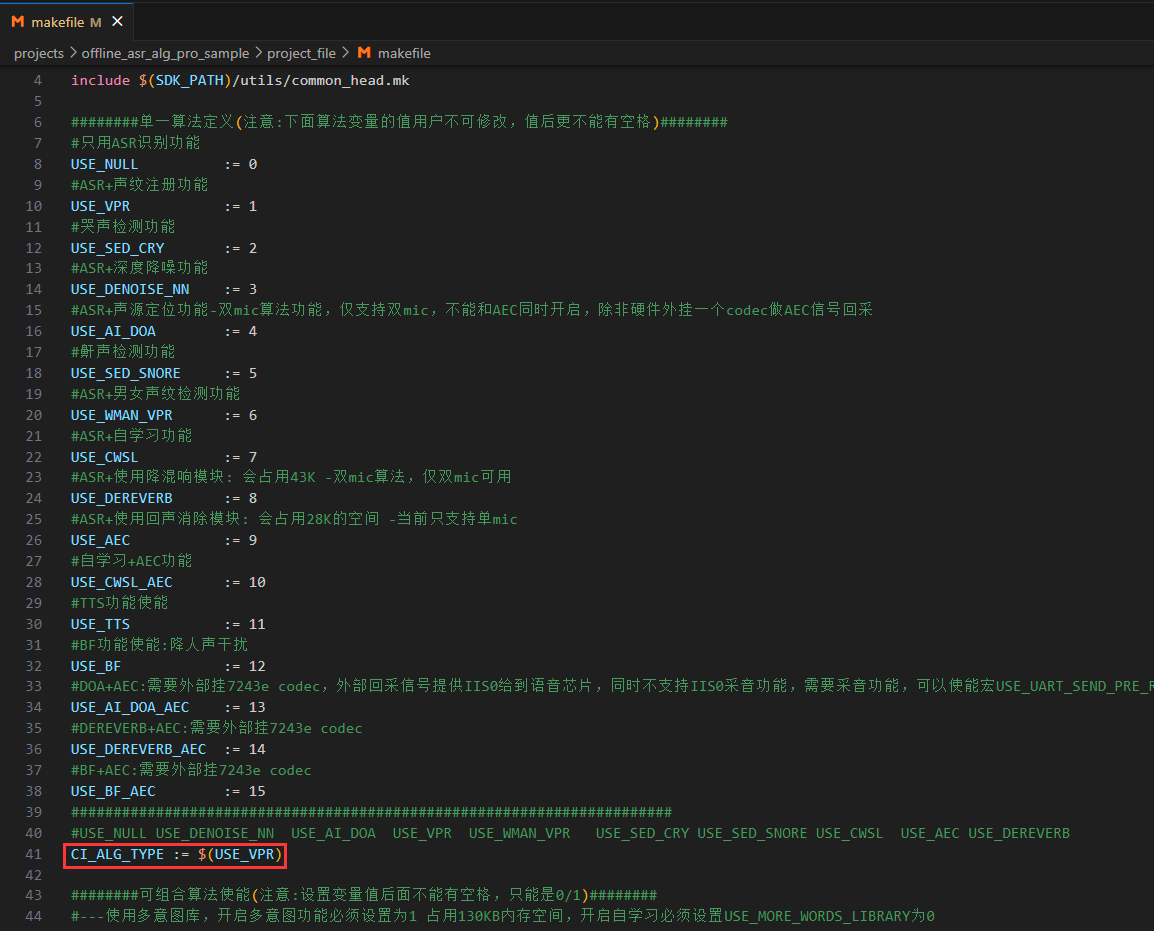
dnn文件夹更换声学模型与算法模型:
声纹注册需搭配该算法的前端算法模型使用,在projects\offline_asr_alg_pro_sample\firmware\dnn文件中,更换与makefile文件里CI_ALG_TYPE对应的算法模型。

可在external\model\vpr(声纹注册)文件夹中,拷贝已有的算法模型。

注意
- 使用声纹注册、男女声纹检测、哭声鼾声检测、深度降噪、声源定位、语音合成、双麦语音增强算法时,需搭配对应的前端算法模型使用。
- 深度降噪算法有针对领域特定dnn声学模型模型。
- 哭声鼾声检测算法不支持语音识别,dnn声学模型可用[0]reserve.bin代替。
2.1 单麦语音识别算法¶
语音识别技术也被称为自动语音识别 Automatic Speech Recognition,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_NULL)
2. 应用功能宏配置与参数说明在projects\offline_asr_alg_pro_sample\app\app_main\user_config.h文件中
板级配置选择,当前SDK默认板级配置为CI-D06GT01D开发版
/*板级配置更多细节请查看:https://document.chipintelli.com/硬件资料-->模块手册
chipintelli提供的部分开发板和模组,可以通过下面的宏选择,也可以参考开发板的板级配置文
件添加自定义板级配置文件*/
#define USE_CI_D02GS01J_BOARD 0 //CI-D0XGS01J,端子模块,芯片型号必须设置为1302
#define USE_CI_D02GS02S_BOARD 0 //CI-D0XGS02S,SMT模块,芯片型号必须设置为1302
#define USE_CI_D12GS01J_BOARD 0 //CI-D0XGS01J,端子模块,芯片型号必须设置为1312JE
#define USE_CI_D06GT01D_BOARD 1 //CI-D06GT01D,开发版,芯片型号必须设置为1306
#define USE_CI_E12GS02J_BOARD 0 //CI-E12GS02J,开发版,芯片型号必须设置为231x
#define USE_CUS_D06GS09S_BOARD 0 //CI_D06GS09S,开发板,型号必须为设置1306-仅配置支持双mic 算法+AEC,其他配置不支持
#define USE_CUS_XXXXXXX_BOARD 0 //用户自定义
通讯串口配置
#define CONFIG_CI_LOG_UART HAL_UART0_BASE //配置log输出使用的串口,请勿与protocol共用同一个串口
#define MSG_COM_USE_UART_EN 1 //0,关闭语音模块通讯协议。1,开启语音模块通讯协议。
#define UART_PROTOCOL_NUMBER (HAL_UART2_BASE) //语音模块协议使用的串口,请勿与log共用同一个串口。
#define UART_PROTOCOL_BAUDRATE (UART_BaudRate9600) //语音模块协议使用的串口波特率。
#define UART_PROTOCOL_VER 2 //语音模块协议版本号:1,一代协议。2,二代协议,255,平台生成协议
#define CLOUD_UART_PROTOCOL_EN 0 //云端协议使能-只有在启英开发者平台做固件配协议能用
#if CLOUD_UART_PROTOCOL_EN
#define CLOUD_CFG_UART_SEND_EN 1 //使能串口发送数据
#define CLOUD_CFG_PLAY_EN 1 //播报音使能
#define CLOUD_CFG_UART_PORT ((UART_TypeDef*)(HAL_UART1_BASE))// HAL_UART0_BASE ~ HAL_UART2_BASE,请勿与log共用同一个串口
#define CLOUD_CFG_UART_BAUND_RATE UART_BaudRate9600
#endif
//**通信串口引脚开漏模式使能配置
//注:推挽模式的IO只能对接3.3V电平的IO,开漏模式可以对接5V电平的IO(外部需要上拉到5V)
#define UART0_PAD_OPENDRAIN_MODE_EN 0 //0,UART0为推挽模式。1,UART0为开漏模式。
#define UART1_PAD_OPENDRAIN_MODE_EN 1 //0,UART1为推挽模式。1,UART1为开漏模式。
#define UART2_PAD_OPENDRAIN_MODE_EN 0 //0,UART2为推挽模式。1,UART2为开漏模式。
语音识别配置
//**语音识别配置
#define USE_SEPARATE_WAKEUP_EN 1 //是否使用独立的唤醒词模型。1:是 0:否。
#define DEFAULT_MODEL_GROUP_ID 1 //模型ID,用于指定上电启动时,默认进入的语言模型。通常0为命令词模型,1为唤醒词模型
#if (!USE_SEPARATE_WAKEUP_EN)
#undef DEFAULT_MODEL_GROUP_ID
#define DEFAULT_MODEL_GROUP_ID 0
#endif
#define PLAY_WELCOME_EN 1 //是否在启动时播放开机提示音。1:是 0:否。
#define PLAY_ENTER_WAKEUP_EN 1 //是否在唤醒时播放提示音。1:是 0:否。
#define PLAY_EXIT_WAKEUP_EN 1 //是否在切换到只监听唤词状态时播放提示音。1:是 0:否。
#define PLAY_OTHER_CMD_EN 1 //是否在识别到命令词时播放提示音。1:是 0:否。
#define ADAPTIVE_THRESHOLD 0
#define ASR_SKIP_FRAME_CONFIG 0
#define EXIT_WAKEUP_TIME 15*1000 //退出唤醒超时时间,单位毫秒。超过此配置指定的时间长度内没有识别到任何命令词,就会切换到只监听唤词状态。
播放器配置
//**播放器配置
#if (VOICE_PLAY_BY_UART && PCM_VOICE_PLAY_BY_UART)
#define AUDIO_PLAYER_ENABLE 0 //是否启用音频播放器。0:不启用,1:启用。不时用播放功能时,
#else
#define AUDIO_PLAYER_ENABLE 1 //是否启用音频播放器。0:不启用,1:启用。不时用播放功能时,
//关闭此功能可以节省内存空间。
#endif
#define PLAYER_CONTROL_PA 0 //是否有播放器控音频功放开关。0:功放常开,1:播放器在需要播放时才打开,但可能增加一点每一次播放的延迟时间
#define VOLUME_MAX 7 //设置音量调节的上限值,对应硬件支持的最大音量。
#define VOLUME_MIN 1 //设置音量调节的下限值,对应最小音量。
#define VOLUME_DEFAULT 5 //设置音量调节的默认值。
#if AUDIO_PLAYER_ENABLE
#define USE_PROMPT_DECODER 1 //播放器是否支持prompt解码器,1:是 0:否。
#define USE_MP3_DECODER 1 //为1时加入mp3解码器,1:是 0:否。
#define AUDIO_PLAY_SUPPT_MP3_PROMPT 1 //播放器是否开启mp3提示音,1:是 0:否。
#endif
OTA功能配置
//**OTA配置
#define CI_OTA_ENABLE (0) //开启OTA功能,需修改打包升级工具版本,在firmware\config.ini文件中设置成firmware_version=FW_V1,升级与被升级固件均要FW_V1版本工具打包生成
#define CI_OTA_UART_NUMBER (1) //uart0:0 uart1:1 uart2:2 ,引脚需使板级配置文件中复用配置为该UART的引脚 \
(注意:bootloader中: uart1-(1306使用PB7和PC0, 其他型号使用PA2和PA3) \
uart2-(1306使用PB1和PB2, 其他型号使用PA5和PA6) \
请严格按照上面管脚设计,否则会出现管脚不对应无法和 \
bootloadr握手成功)
#define CI_OTA_UART_BAUD (UART_BaudRate115200) //同bootloader握手波特率
红外功能配置 红外功能需使用红外码库,firmware文件请替换external\firmware参考\ir(红外)\firmware。
//*红外功能配置
#define USE_IR_ENABEL 1 //红外功能,1:是 0:否。开启红外功能在使用打包工具升级固件时,请取消勾选“升级完成自动运行”,防止重复烧录
#if USE_IR_ENABEL
#define UART_CONTOR_SEND_IR 0 //用通信口进行串口协议控制发红外
#define IR_TEST 0 //用通信口进行串口协议的产检
#ifndef USE_NIGHT_LIGHT
#define USE_NIGHT_LIGHT 1
#endif
#endif
语音上传和播放配置(通过串口)
//*语音上传和播放配置(通过串口)
#define VOICE_UPLOAD_BY_UART (0) //通过串口上传语音功能配置,消耗75KB内存
#define AUDIO_COMPRESS_SPEEX_ENABLE 1 //音频压缩算法。 1-处理使能SPEEX压缩后的数据 0-直接传输PCM数据
#if (VOICE_UPLOAD_BY_UART&&(!USE_NULL||USE_PWK)) //语音上传功能不能开算法
#error "ONLY USE_NULL WITH NO PWK SUPPORT VOICE_UPLOAD_BY_UART!"
#endif
#define VOICE_PLAY_BY_UART (0) //通过串口接收音频数据播放配置
#if (VOICE_UPLOAD_BY_UART || VOICE_PLAY_BY_UART)
#define INNER_CODEC_AUDIO_IN_USE_RESAMPLE 0 //默认打开 0:不开重采样 1:打开重采样
#endif
#if (VOICE_PLAY_BY_UART)
#define PCM_VOICE_PLAY_BY_UART (1) //播放PCM格式 PCM和MP3格式只能选一个
#define MP3_VOICE_PLAY_BY_UART (!PCM_VOICE_PLAY_BY_UART) //播放MP3格式 PCM和MP3格式只能选一个,仅支持播放采样率16k且单声道音频数据
#define AUDIO_PLAY_USE_OUTSIDE (1) //启用自定义外部数据源播放
#endif
CI231X芯片蓝牙功能配置,板级配置需选择USE_CI_E12GS02J_BOARD
//BLE相关协议
#if USE_BLE
#define EXTERNAL_CRYSTAL_OSC_FROM_RF 1 //蓝牙端使用外部晶振, 语音端时钟由蓝牙端提供-用户不可修改
#define CIAS_BLE_CONNECT_MODE_ENABLE 1 //ble连接模式使能
#define CIAS_BLE_SCAN_ENABLE 1 //ble连接模式使能, 同时广播开启扫描功能
#define CIAS_BLE_ADV_GROUP_MODE_ENABEL 0 //ble纯广播模式-不推荐使用
#define CIAS_BLE_DEBUG_ENABLE 0 //ble 测试模式-客户一般用不上
#define BLE_CONNECT_TIMEOUT 8 //蓝牙连接超时时间(S),超时会重启蓝牙协议栈,设置为0则表示不进行超时判断
#define BLE_NAME_MAX_LEN 18 //蓝牙广播名称最大长度
#define RF_RX_TX_MAX_LEN 20 //蓝牙收发数据最大长度为20,一般不用修改
#define CIAS_PROTOCOL_VER 1 //和小程序通信协议版本:1-V1.0 2-V1.1
#define CIAS_BLE_USE_DEFAULT_ADV_DATA 1 //和启英小程序配合使用
#define CIAS_BLE_APP_CMD 1 //小程序调用用户层事件回调函数
#define DEV_DRIVER_EN_ID DEV_LIGHT_CONTROL_MAIN_ID //蓝牙广播设备类型
#endif //USE_BLE
其余功能配置
//**mic数量配置
#ifndef HOST_MIC_USE_NUMBER
#define HOST_MIC_USE_NUMBER 1 //定义mic数量
#endif
//**麦克风电路模式配置
#define MIC_DIFF_SINGLE 0 /*1,单端。0,差分(通用模块都是差分模式,省成本的模块为单端(MICN_L 接GND)时,需要配置为SINGLE))*/
//**IIS采音功能开关配置
#ifndef USE_IIS1_OUT_PRE_RSLT_AUDIO
#define USE_IIS1_OUT_PRE_RSLT_AUDIO 0 //1,开启IIS采音功能,可以使用采音板彩音,占用PA2~PA6。
//0,关闭IIS采音功能,PA2~PA6可以用于其它功能。
#endif
//**时钟源配置
#if ((CI_CHIP_TYPE == 1312) || (CI_CHIP_TYPE == 1311))
#define USE_EXTERNAL_CRYSTAL_OSC 0
#else
#define USE_EXTERNAL_CRYSTAL_OSC 1 //0:使用内部RC作为时钟源。1:使用外部晶振作为时钟源。
#endif
//**波特率自适应功能配置
#if (USE_EXTERNAL_CRYSTAL_OSC == 0) //使用内部RC时,建议开启波特率自适应(需要电控增加对应支持)。
#define UART_BAUDRATE_CALIBRATE 1 //是否使能波特率自适应功能。
#define BAUDRATE_SYNC_PERIOD 300000 // 波特率同步周期,单位毫秒。
#define BAUDRATE_FAST_SYNC_PERIOD 5000 // 一次波特率同步失败后,下一次同步间隔,单位毫秒。
#define BAUD_CALIBRATE_MAX_WAIT_TIME 400 // 等待反馈包的超时时间,单位毫秒。
#endif
2.2 声纹注册算法¶
声纹识别算法当前推荐最多注册4个人,人数越多会影响注册效果,如需注册更多人数,需确认效果达到使用要求。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_VPR)
2. 该算法参数宏说明在projects\offline_asr_alg_pro_sample\app\app_main\user_config.h文件中
#if USE_VPR
#define VP_USE_FRM_LEN 1200 //声纹计算的窗长,单位为ms, 建议范围1200-1500,值越大消耗内存越多(每增加100,内存增加8KB)
#define VP_CMPT_SKIP_NUM 0 //-不可修改
#define VP_THR_FOR_MATCH (0.52f) //声纹阈值-建议范围(0.48-0.68),值越大,灵敏度越低,误识越低,识别率下降,需要更严格的匹配注册的模版
#define VP_THR_FOR_SAME_MATCH (0.50f) //同一用户,判断是否重复所用声纹阈值-不可修改
#define VP_SLIDE_TIME_PER_CMPT 3 //声纹每次计算,滑窗-不可修改
#define VP_REC_TIMES 3 //声纹注册时重复录入次数 -注册时的次数
#define MAX_VP_TEMPLATE_NUM 3 //声纹识别功能允许的最大模版(用户)数,最大4个 重要说明:每个模版单次约占0.8KB NV空间,三次2.4KB
#define MAX_VP_REG_TIME 10 //注册声纹时最大超时等待时间(秒)
#define NVDATA_ID_VP_NUMBER 0xA0000001 //存储模板数量NV基地址 -不可修改
#define NVDATA_ID_VP_INFO 0xA0000002 //存储模板ID NV基地址,每个用户模版数是重复录入次数-不可修改
//输出给用户的id就是(地址-0xA0000002/VP_REC_TIMES
#define NVDATA_ID_VP_MODE 0xA0000003 //存储模板NV基地址 -不可修改
#if (MAX_VP_TEMPLATE_NUM > 4)
#error "The vpr template num max 4\n"
#endif
#endif
3. 该算法相关应用函数在components\VPR\voice_print_recognition.c文件中
声纹注册:调用接口:vpr_start_regist
/**
* @brief 开始注册声纹模板
* @return 0:启动声纹注册成功; -1:启动声纹注册失败。
*/
int vpr_start_regist();
声纹识别:注册之后,识别到命令词之后,调用 vpr_run_one_recognition,进行识别
/**
* @brief 执行一次声纹识别
* @return 0:没有错误; 非0:错误号。
*/
int vpr_run_one_recognition();
删除声纹:调用 vpr_clear 删除指定声纹模板,调用 vpr_clear 删除所有模板
/**
* @brief 删除指定的声纹模板
* @return 0:没有错误; -1:指定的模板号非有效模板(未注册或者已被删除)。
*/
int vpr_delete();
/**
* @brief 删除所有声纹模板
* @return 0:没有错误; 非0:错误号。
*/
int vpr_clear();
4. projects\offline_asr_alg_pro_sample\firmware\dnn文件夹中,声纹注册算法请选择external\model\vpr(声纹注册)中[60001]VPR_model_v00xx.bin算法模型
注意
- 声纹注册算法,涉及收费,需烧录license,具备license的芯片正常运行,无license的芯片每五分钟会进行复位,如有量产需求,请联系启英泰伦商务。
- 固件打包时,如果NV data分区空间过小,影响模板数据存储,导致无法正常识别已注册的声纹。
- 声纹注册需搭配该算法的前端算法模型使用。
2.3 男女声纹检测算法¶
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_WMAN_VPR)
2. 该算法参数宏说明在projects\offline_asr_alg_pro_sample\app\app_main\user_config.h文件中
#if USE_WMAN_VPR
#define VP_USE_FRM_LEN 1200 //声纹计算的窗长,单位为ms,建议范围1200-1500,值越大消耗内存越多(每增加100,内存增加8KB)
#define VP_CMPT_SKIP_NUM 0
#define NVDATA_ID_VP_NUMBER NVDATA_ID_VP_MOULD_INFO //存储已添加了的模板数量-不可修改
#define VP_SLIDE_TIME_PER_CMPT 1 //声纹每次计算,滑窗的次数-不可修改
#define WMAN_PLAY_EN 1 //男女声纹识别播报
#endif
3. 该算法相关应用函数在components\VPR\voice_print_wman_recognition.c文件中
/**
* @brief 执行一次声纹识别
* @return 0:没有错误; 非0:错误号。
*/
int vpr_run_one_recognition()
4. projects\offline_asr_alg_pro_sample\firmware\dnn文件夹中,男女声纹检测算法请选择external\model\wman_vpr(男女声纹)中[60008]VGR_model_xxxx_vx算法模型
注意
- 男女声纹检测算法,涉及收费,需烧录license,具备license的芯片正常运行,无license的芯片每五分钟会进行复位,如有量产需求,请联系启英泰伦商务。
- 男女声纹检测需搭配该算法的前端算法模型使用。
2.4 哭声与鼾声检测算法¶
哭声鼾声检测算法, 检测环境中出现的目标声音事件,不支持语音识别功能。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE进行修改,哭声算法修改成CI_ALG_TYPE := $(USE_SED_SNORE),鼾声算法修改成CI_ALG_TYPE := $(USE_SED_SNORE)
2. 该算法参数宏说明在projects\offline_asr_alg_pro_sample\app\app_main\user_config.h文件中
#define NO_ASR_FLOW 1 //不可修改
#if USE_SED_CRY
#define THRESHOLD_CRY 0.55f //可根据具体需求修改,范围为(0~1)float类型-建议范围(0.5-0.6f),值越大,灵敏度越低
#define TIMES_CRY 3 //可根据具体需求修改,最大5次(算法计算几次给结果)
#elif USE_SED_SNORE
#define THRESHOLD_SNORE 0.53f //可根据具体需求修改,范围为(0~1)float类型-建议范围(0.5-0.6f),值越大,灵敏度越低
#define TIMES_SNORE 3 //可根据具体需求修改,最大5次(算法计算几次给结果)
#endif
#if TIMES_CRY > 5
#error "The times should be less than or equal to 5\n"
#endif
3. 该算法相关应用函数在projects\offline_asr_alg_pro_sample\app\app_sed\sed_app_host.c文件中
/**
* @brief 声音检测,打印当前检测值,值越高说明该音频是目标音频的概率就越高
*/
void sed_rslt_cb();
/**
* @brief 检测到声音输出函数
*/
void sed_rslt_out(void)
4. projects\offline_asr_alg_pro_sample\firmware\dnn文件夹中,哭声检测算法请选择external\model\sed_cry(哭声检测)中[60002]sed_cryx_mxx.bin算法模型,鼾声检测算法请选择external\model\sed_snore(鼾声检测)中[60005]sed_snorex_mxx.bin算法模型
注意
- 哭声与鼾声检测算法,涉及收费,需烧录license,具备license的芯片正常运行,无license的芯片每五分钟会进行复位,如有量产需求,请联系启英泰伦商务。
- 哭声鼾声检测算法不支持语音识别,dnn声学模型可用[0]reserve.bin代替。
- 哭声鼾声检测需搭配该算法的前端算法模型使用。
2. 5 深度降噪算法¶
深度降噪法算抑制设备本身产生的高噪声,以提升低信噪比环境下的识别率,针对不同应用领域需使用对应的领域模型,当前版本默认提供了烟机和窗帘的降噪模型。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_DENOISE_NN)
2. projects\offline_asr_alg_pro_sample\firmware\dnn文件夹中,深度降噪算法请选择external\model\nn_denoise(深度降噪)中[60003]nn_denoise_xx.bin算法模型
注意
- 深度降噪需搭配该算法的前端算法模型使用。
2.6 双麦声源定位算法¶
DOA算法为双mic算法可进行声源方位角度估计,当前版本支持0-180度检测范围,分辨率为10°,双mic位置需处于同一平面相同朝向,推荐麦间距为4cm~6cm。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_AI_DOA)
2. 该算法参数宏说明在projects\offline_asr_alg_pro_sample\app\app_main\user_config.h文件中
#if USE_AI_DOA
#define AI_DOA_OUT_TYPE 3 //doa输出类型:1-唤醒词输出角度 2-命令词输出角度 3-唤醒次和命令词都输出角度
#endif
/**
* @brief 角度信息输出
*/
void ci_doa_get_cb(int audio_state, int doa_angle)
4. projects\offline_asr_alg_pro_sample\firmware\dnn文件夹中,声源定位算法请选择external\model\doa(声源定位)中[60004]nn_dual_mic_doa_vxxxx.bin算法模型
注意
- 双mic位置需处于同一平面相同朝向,推荐麦间距为4cm~6cm。
- 声源定位算法支持多种不同方式输出角度信息,可通过AI_DOA_OUT_TYPE宏来设置。
- 声源定位需搭配该算法的前端算法模型使用。
2.7 自学习算法¶
在非联网状态,用户通过语音对话的方式,更改默认的命令词;该种更改方式满足终端用户的个性化自定义的需求,可以给客户带来更好的用户体验。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_CWSL)
2. 该算法参数宏说明在projects\offline_asr_alg_pro_sample\app\app_main\user_config.h文件中
#define CWSL_WAKEUP_NUMBER 2 // 可学习的唤醒词数量
#define WAKE_UP_ID 1 // 学习的唤醒词对应的命令词ID
#define CWSL_REG_TIMES 1 // 学习时 每个词需说几遍,默认 1 遍即可,支持1、2遍,FOR_REG_2TIMES_FLOW_V2 配置 1时,最大支持 3 遍;
#define CWSL_WAKEUP_THRESHOLD 37 // 学习的唤醒词阈值门限,越小越灵敏,默认 37, 最小可配置到 32;
#define CWSL_CMD_THRESHOLD 35 // 学习的命令词阈值门限,越小越灵敏,默认 35,最小可配置到 30;
#define FOR_REG_2TIMES_FLOW_V2 0 // 学习时,说两遍/三遍逻辑,版本二流程,后续均和第一次的比较,一致学习成功,不一致,最多支持说 3 次,FOR_REG_2TIMES_FLOW_V2 配置 1时, CWSL_REG_TIMES 必须是 2或3
#define CWSL_REG_VAD_LEVEL 0 // 学习过程,灵敏度选项配置: 0 低灵敏度,可减少噪声对学习的干扰,需学习过程大声说话;1 高灵敏度,但也可以导致干扰噪声干扰学习
#define CICWSL_TOTAL_TEMPLATE 16 //可存储模板数量
#if (CWSL_REG_TIMES == 3)
#define FOR_REG_2TIMES_FLOW_V2 1
#elif (CWSL_REG_TIMES > 3)
#error "The CWSL_REG_TIMES max 3\n"
#endif
3. 该算法相关应用函数在projects\offline_asr_alg_pro_sample\app\app_cwsl\cwsl_app_handle.c文件中
/*
* @brief 命令词自学习消息处理函数
* @param asr_msg ASR识别结果消息
* @param cmd_handle 命令词handle
* @param cmd_id 命令词ID
* @retval 1 数据有效,消息已处理
* @retval 0 数据无效,消息未处理
*/
uint32_t cwsl_app_process_asr_msg(sys_msg_asr_data_t *asr_msg, cmd_handle_t *cmd_handle, uint16_t cmd_id)
/*
* @brief 模块初始化事件响应,命令词自学习参数初始函数,初始会调用该函数
* @param cwsl_init_parameter 参数指针
* @retval 1 必须返回可学习的模板数量
*/
int on_cwsl_init(cwsl_init_parameter_t *cwsl_init_parameter)
/*
* @brief 学习开始事件响应,每次学习开始调用该函数
* @param cmd_id 命令词ID
* @param group_id 组ID
* @param word_type 学习的类型,CMD_WORD 命令词 ;WAKEUP_WORD唤醒词
* @retval 0
*/
int on_cwsl_reg_start(uint32_t cmd_id, uint16_t group_id, cwsl_word_type_t word_type)
/*
* @brief 学习停止事件响应
* @param 无
* @retval 0
*/
int on_cwsl_reg_abort()
/*
* @brief 录制开始事件响应
* @param 无
* @retval 0
*/
int on_cwsl_record_start()
/*
* @brief 录制结束事件响应
* @param times 当前学习的次数
* @param result 当前学习结果的状态:学习成功,学习失败,...
* @retval 0
*/
int on_cwsl_record_end(int times, cwsl_reg_result_t result)
/*
* @brief 删除模板成功事件响应
* @retval 0
*/
int on_cwsl_delete_successed()
/*
* @brief 识别成功事件响应
* @param cmd_id 命令词ID
* @param distance 参数未使用,当前无效
* @retval 0
*/
int on_cwsl_rgz_successed(uint16_t cmd_id, uint32_t distance)
/*
* @brief 开始启动学习
* @param word_type 学习的命令词类型
* @retval 0
*/
void cwsl_app_reg_word(cwsl_word_type_t word_type)
/*
* @brief 删除指定类型模板
* @param cmd_id 指定要删除的命令词ID, 传入-1为通配符,忽略此项
* @param group_id 指定要删除的命令词分组号, 传入-1为通配符,忽略此项
* @param word_type 指定要删除的命令词类型,传入传入-1为通配符,忽略此项
* @retval 无
*/
void cwsl_app_delete_word(uint32_t cmd_id, uint16_t group_id, cwsl_word_type_t word_type)
4. 自学习命令词播报音配置在projects\offline_asr_alg_pro_sample\app\app_cwsl\cwsl_app_handle.c文件中配置reg_cmd_list结构体数组
//左边一列表示的是要学习的命令词ID,右边一列表示需要播报的ID
const cwsl_reg_asr_struct_t reg_cmd_list[]=
{ //命令词ID //学习提示播报音ID
{2, 1001},
{3, 1002},
{4, 1003},
{5, 1004},
{6, 1005},
{7, 1006},
};
5. 如果对projects\offline_asr_alg_pro_sample\firmware\user_file\cmd_info下的命令词列表中命令词ID进行修改,还需要将projects\offline_asr_alg_pro_sample\app\app_cwsl\cwsl_app_handle.h文件中枚举cicwsl_func_index进行修改,枚举如下:
typedef enum
{
CWSL_REGISTRATION_WAKE = 200, ///< 命令词:学习唤醒词
CWSL_REGISTRATION_CMD = 201, ///< 命令词:学习命令词
CWSL_REGISTER_AGAIN = 202, ///< 命令词:重新学习
CWSL_EXIT_REGISTRATION = 203, ///< 命令词:退出学习
CWSL_DELETE_FUNC = 204, ///< 命令词:我要删除
CWSL_DELETE_WAKE = 205, ///< 命令词:删除唤醒词
CWSL_DELETE_CMD = 206, ///< 命令词:删除命令词
CWSL_EXIT_DELETE = 207, ///< 命令词:退出删除模式
CWSL_DELETE_ALL = 208, ///< 命令词:全部删除
CWSL_REGISTRATION_NEXT = 199, ///< 播报:学习下一个
//CWSL_DATA_ENTERY_SUCCESSFUL = 209, ///< 播报:录入成功
CWSL_DATA_ENTERY_FAILED = 210, ///< 播报:学习失败
CWSL_REGISTRATION_SUCCESSFUL = 211, ///< 播报:学习成功
CWSL_TEMPLATE_FULL = 212, ///< 播报:学习模板超过上限
CWSL_SPEAK_AGAIN = 219, ///< 播报:请再说一次>
CWSL_TOO_SHORT = 220, ///< 播报:语音长度不够,请再说一次>
CWSL_DELETE_SUCCESSFUL = 213, ///< 播报:删除成功
CWSL_REGISTRATION_ALL = 217, ///< 播报:学习完成
CWSL_REG_FAILED = 218, ///< 播报:学习失败
CWSL_REG_FAILED_DEFAULT_CMD_CONFLICT = 221, ///< 播报:与默认指令冲突,请换种说法
}cicwsl_func_index;
2.8 双麦降混响算法¶
该算法在混响的情况下配合多麦克能提升识别效果,单麦不支持。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_DEREVERB)
2.9 回声消除算法¶
该算法在有参考的情况下,自适应追踪回声路径的变换、实时抑制扬声器到达麦克风终端的回声信号,以提升目标语音的识别效果。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_AEC)
2. 回声消除涉及硬件参考信号线路的设计,如果贵司自行设计硬件, 请联系启英泰伦技术支持
2.10 命令词自学习加回声消除算法¶
该算法支持非联网状态,用户通过语音对话的方式,更改默认的唤醒词和命令词;支持在有参考的情况下,自适应追踪回声路径的变换、实时抑制扬声器到达麦克风终端的回声信号,以提升目标语音的识别效果。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_CWSL_AEC)
2. 自学习相关参数与应用函数说明请查看☞自学习算法
3. 回声消除涉及硬件参考信号线路的设计,如果贵司自行设计硬件, 请联系启英泰伦技术支持
2.11 语音合成TTS算法¶
语音合成算法是一种将文本转换为声音信号的技术,又称为文本转换语音技术(TextToSpeech,TTS),多应用于ETC、公交智能报站器、叫号系统等领域。
1. 文本合成TTS算法涉及前端算法模型和相关库文件,firmware文件请替换external\firmware参考\tts\firmware。
2. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_TTS)
3. 该算法参数宏说明在projects\offline_asr_alg_pro_sample\app\app_main\user_config.h文件中
#if USE_TTS
#define UART_TTS_NUMBER HAL_UART1_BASE //TTS文本合成通信串口号
#define UART_TTS_IRQ UART1_IRQn //TTS文本合成通信串口中断号
#define UART_TTS_BAUDRATE UART_BaudRate115200 //TTS文本合成通信串口波特率
#endif
4. 该算法相关应用函数在components\msg_com\voice_module_uart_tts_protocol.c文件中
/*
* @brief 发送音量语速语调
* @param msg TTS串口数据发送队列
* @retval 0 高优先级任务未触发
* @retval 1 高优先级任务触发,任务切换
*/
int vmup_port_send_packet_rev_play_parameter_msg(sys_tts_msg_com_data_t *msg)
/*
* @brief 发送其他普通命令
* @param msg TTS串口数据发送队列
* @retval 0 高优先级任务未触发
* @retval 1 高优先级任务触发,任务切换
*/
int vmup_port_send_packet_rev_cmd_msg(sys_tts_msg_com_data_t *msg)
/*
* @brief 发送其他普通命令
* @param msg TTS串口数据发送队列
* @retval 0 高优先级任务未触发
* @retval 1 高优先级任务触发,任务切换
*/
int vmup_port_send_packet_rev_text_msg(sys_tts_msg_com_data_t *msg)
/*
* @brief TS接收串口数据进行组包处理
* @param msg TTS串口接收数据,数据支持GB2312编码格式
* @retval 无
*/
void vmup_tts_receive_packet(uint8_t receive_char)
5. 该算法Demo使用说明,Demo使用涉及”启英泰伦-语音开发工具”,请前往启英泰伦语音AI平台开发资料中下载“三代芯片OTA资料包”获取chipintelli-audio-tools_offline_release_vx.x.x.exe。
打开启英泰伦-语音开发工具,选择 TTS串口工具功能,通信串口配置与代码中TTS串口配置一样后打开串口。
输入待合成文本或加载默认文本后,点击开始合成 ,工具将把光标起始后的文本内容使用通信串口发送协议数据给语音芯片,芯片通过日志串口打印出文本信息并进行播报。
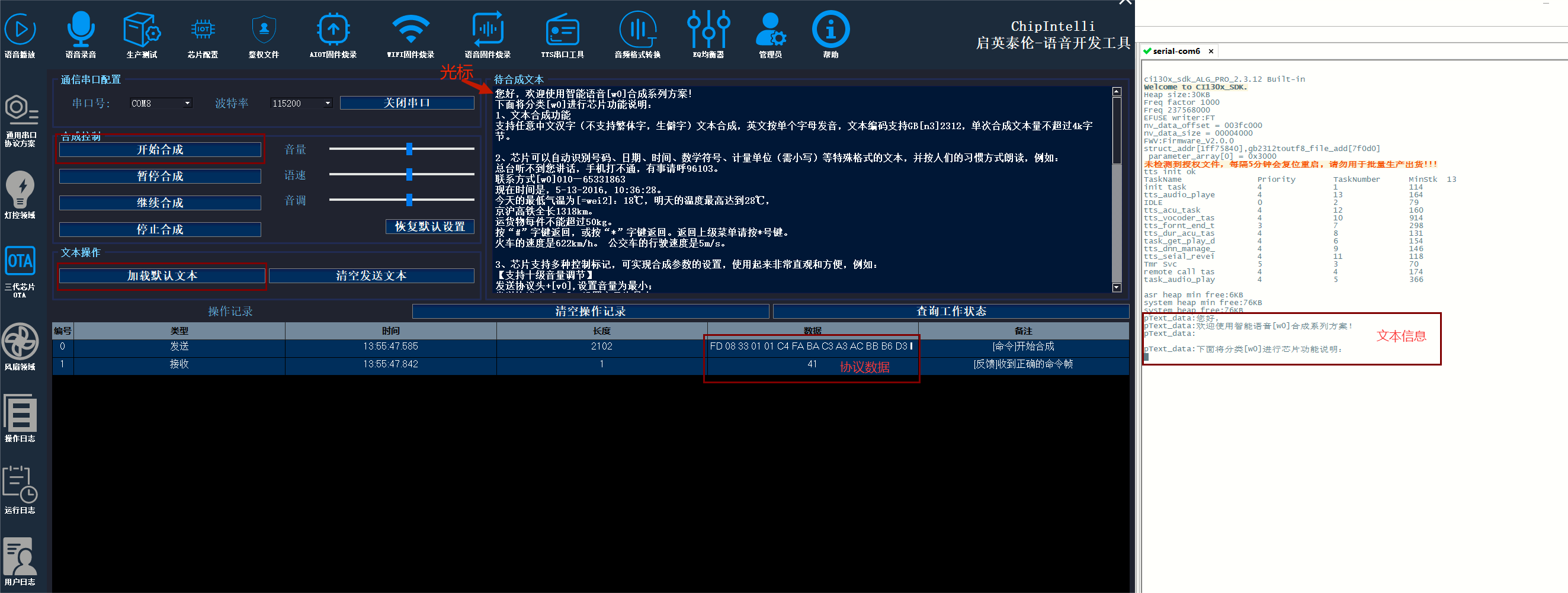
注意
- 文本合成TTS算法,涉及收费,需烧录license,具备license的芯片正常运行,无license的芯片每10秒会进行复位,如有量产需求,请联系启英泰伦商务。
- TTS串口接收数据支持GB2312编码格式,GB2312将转换utf-8格式进行后续处理。
- 从端接收协议buffer大小限制,协议数据长度请不要超过3000个字节,超出协议数据可能会解析出错。
2.12 双麦语音增强算法¶
双麦语音增强算法主要用于噪声环境下,抑制噪声和干扰,增强目标语音,只支持双mic,双mic位置需处于同一平面相同朝向,推荐麦间距为4cm~6cm。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_BF)
2. 双麦语音增强算法会开启声源定位功能,请在projects\offline_asr_alg_pro_sample\firmware\dnn文件夹中,添加external\model\doa(声源定位)中[60004]nn_dual_mic_doa_vxxxx.bin算法模型
3. 声源定位相关参数与应用函数说明请查看☞双麦声源定位算法
2.13 双麦声源定位加回声消除算法¶
该算法可进行声源方位角度估计,当前版本支持0-180度检测范围,分辨率为10°,并且有参考的情况下,自适应追踪回声路径的变换、实时抑制扬声器到达麦克风终端的回声信号,以提升目标语音的识别效果。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_AI_DOA_AEC)
2. 开启声源定位功能,请在projects\offline_asr_alg_pro_sample\firmware\dnn文件夹中,添加external\model\doa(声源定位)中[60004]nn_dual_mic_doa_vxxxx.bin算法模型
3. 声源定位相关参数与应用函数说明请查看☞双麦声源定位算法
4. 回声消除涉及硬件参考信号线路的设计,如果贵司自行设计硬件, 请联系启英泰伦技术支持
注意
- 该算法属于外挂codec方案,需外部挂7243e codec。
2.14 双麦降混响加回声消除算法¶
该算法在混响的情况下配合多麦克能提升识别效果,单麦不支持,并且在有参考的情况下,自适应追踪回声路径的变换、实时抑制扬声器到达麦克风终端的回声信号,以提升目标语音的识别效果。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_DEREVERB_AEC)
2. 回声消除涉及硬件参考信号线路的设计,如果贵司自行设计硬件, 请联系启英泰伦技术支持
注意
- 该算法属于外挂codec方案,需外部挂7243e codec。
2.15 双麦语音增强加回声消除算法¶
该算法主要用于噪声环境下,抑制噪声和干扰,增强目标语音,并且在有参考的情况下,自适应追踪回声路径的变换、实时抑制扬声器到达麦克风终端的回声信号,以提升目标语音的识别效果。
1. 打开offline_asr_alg_pro_sample\project_file\makefile文件,对CI_ALG_TYPE修改为CI_ALG_TYPE := $(USE_BF_AEC)
2. 该算法会开启声源定位功能,请在projects\offline_asr_alg_pro_sample\firmware\dnn文件夹中,添加external\model\doa(声源定位)中[60004]nn_dual_mic_doa_vxxxx.bin算法模型
3. 声源定位相关参数与应用函数说明请查看☞双麦声源定位算法
4. 回声消除涉及硬件参考信号线路的设计,如果贵司自行设计硬件, 请联系启英泰伦技术支持
注意
- 该算法属于外挂codec方案,需外部挂7243e codec。
2.16 声音能量值计算算法¶
声音能量值计算算法识别到词条输出语音分贝值。
1. 使用就近唤醒算法,打开offline_asr_alg_pro_sample\project_file\makefile文件,修改USE_PWK_ENABLE:= 1
2. 该算法相关应用函数,在projects\offline_asr_alg_pro_sample\app\app_main\system_msg_deal.c文件中
/**
* @brief 音频能量值信息输出
*/
void ci_pwk_get_cb(int db_val)
{
mprintf("--------pwk db val: %ddb\n", db_val);
}
2.17 自动增益控制算法¶
1. 使用自动增益控制算法,打开offline_asr_alg_pro_sample\project_file\makefile文件,修改USE_ALC_AUTO_SWITCH_MODULE:= 1
2. 当前版本自动增益控制算法仅单mic可用,只对68dB以上的稳态噪声有效