命令词和固件制作指南¶
1. 语音识别处理流程及所需资源¶
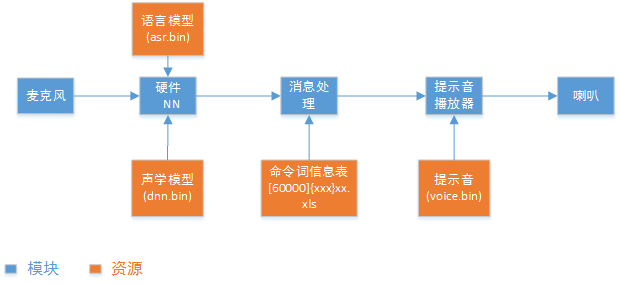
语音识别的流程及所需资源如下图所示,麦克风将语音转换为数字信号,送到NN做识别。NN识别需要两个资源,声学模型和语言模型,NN识别后输出字符串。然后到命令词信息表里查找NN输出的字符串,如果未找到,说明误识别,不处理。如果查找到,就是有效识别,然后根据查找到的命令词获取相关信息,进行相应应用功能处理,最后调用提示音播放器播放提示音。
注解
- 语言模型:根据命令词生成,用于NN识别;
- 声学模型:用于NN识别,一般根据语言,应用场景等因数相关;
- 命令词信息表:用于保存命令词相关的信息,比如命令字符串、是否是唤醒词、对应的提示音等等;
- 提示音:用于识别到命令词后,做相应的反馈提示,当前支持mp3。
后面的章节会介绍如何生成所需的资源。
2. 制作命令词模型文件¶
2.1. 进入模型制作界面¶
- 登录 ☞启英泰伦语音AI平台 , 如下图所示,点击左菜单栏(语言模型)选项图标进入语言模型界面:
- 创建项目:
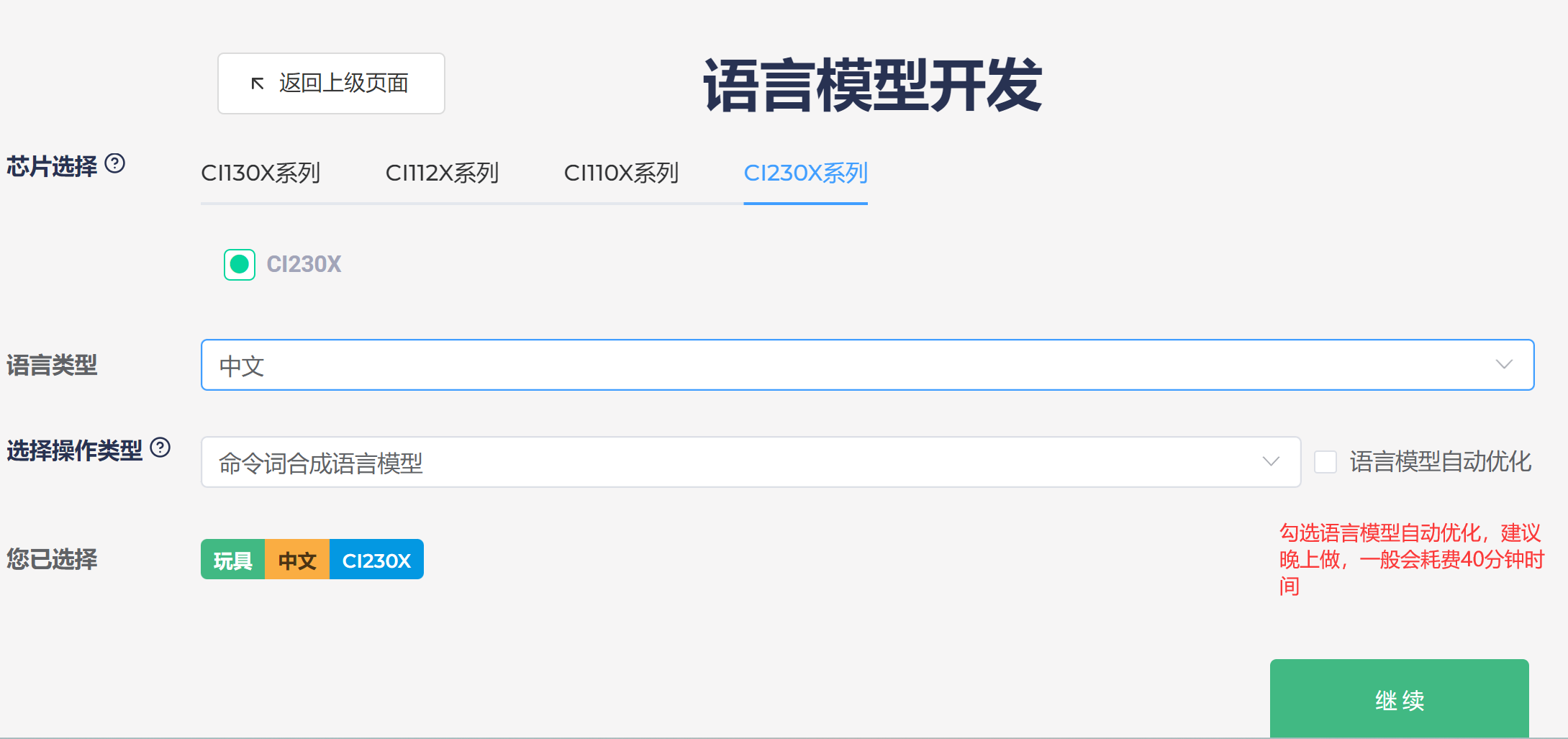
- 模型制作界面:
2.2. 生成和下载声学模型¶
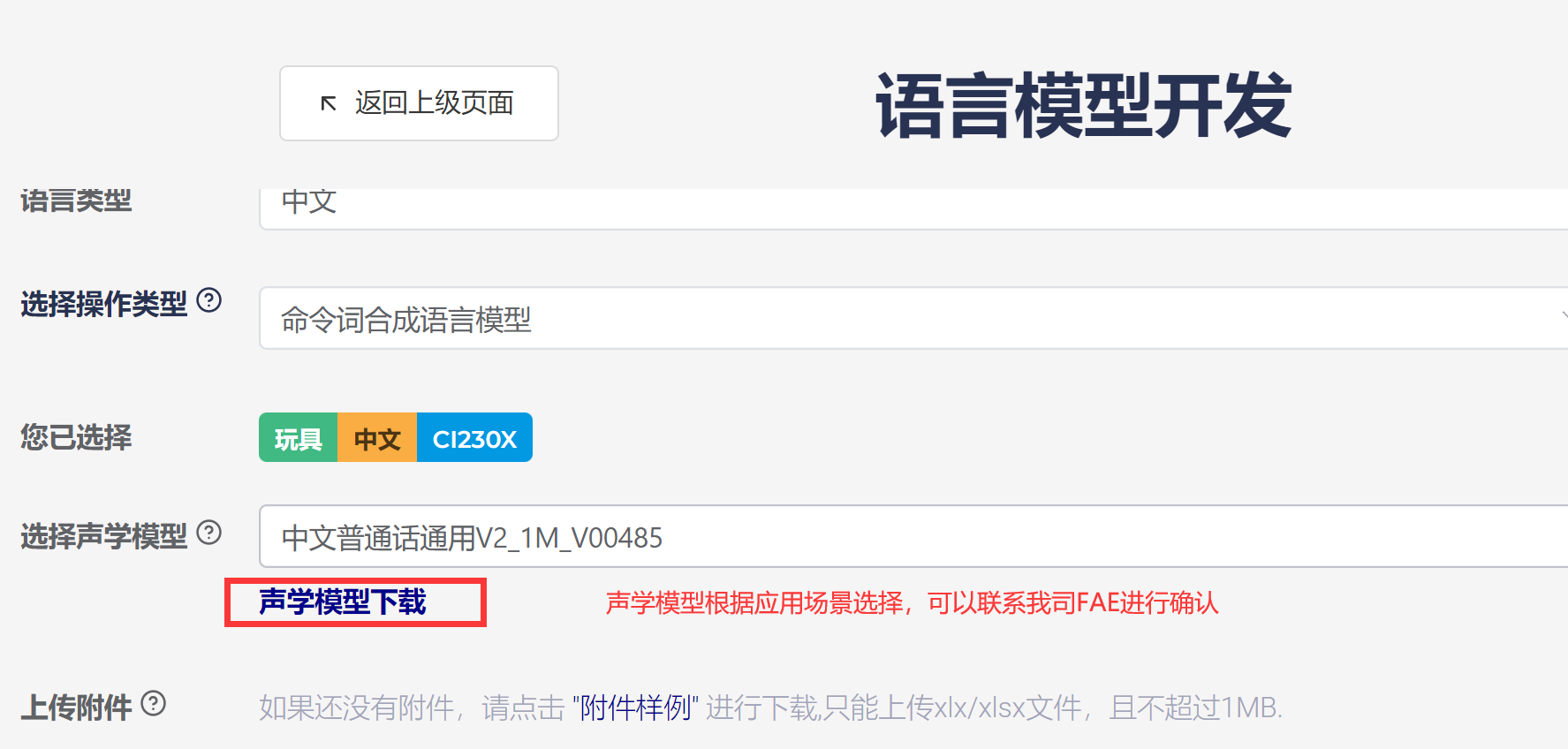
1、填写项目名称;
2、选择芯片型号CI230X系列芯片;
3、选择产品类型;
4、选择语言类型;
5、选择声学模型类型;
6、点击声学模型下载,下载声学模型,解压下载的声学模型压缩包,可以得到对应的声学模型文件。
- 解压下载的声学模型压缩包,可以得到声学模型:

2.3. 生成和下载语言模型¶
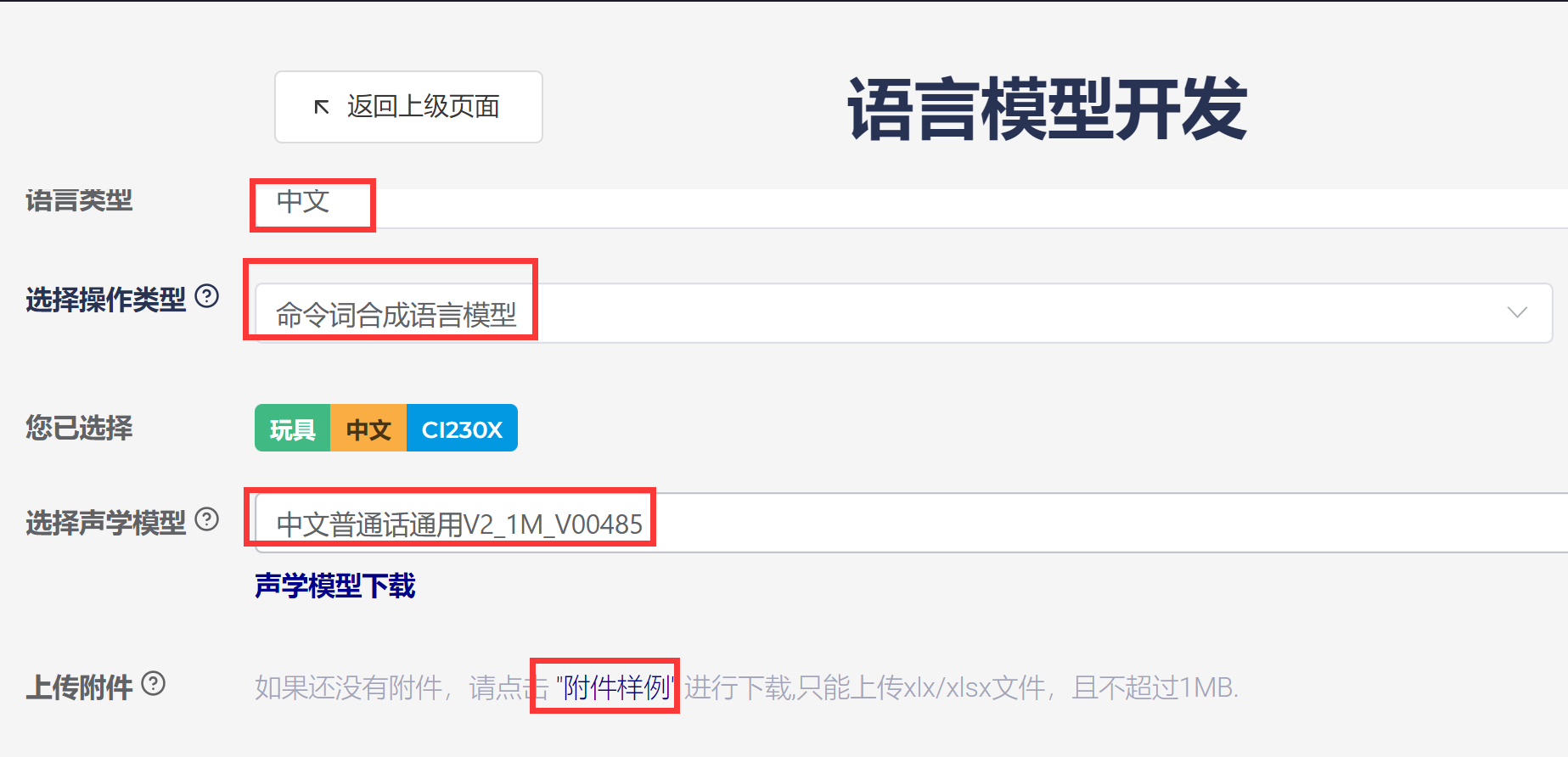
- 先填写语言类型,下载对应语言的模板文件:
1、语言类型:下拉框选择中文、英文、日文。
2、下载样例:根据语言类型选择,会出现中文、英文、日文样例。
- 打开下载的中文模板文件,参照文件格式,编辑命令词:
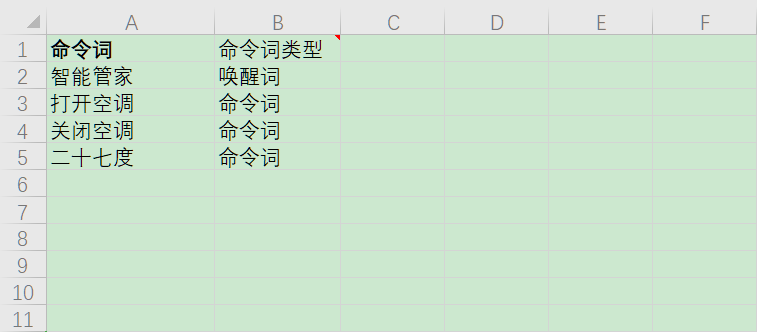
注解
- 命令词:需要语音识别的命令词字符串。 2. 命令词类型:指定命令词是否为唤醒词,如果指定了唤醒词,平台会生成双网络数据。 3. 双网络:是指为了改善唤醒词的识别效果,为唤醒词单独做一个识别模型,其他的命令词做一个识别模型,就相当于这个项目用到了两个神经网络模型,简称双网络。
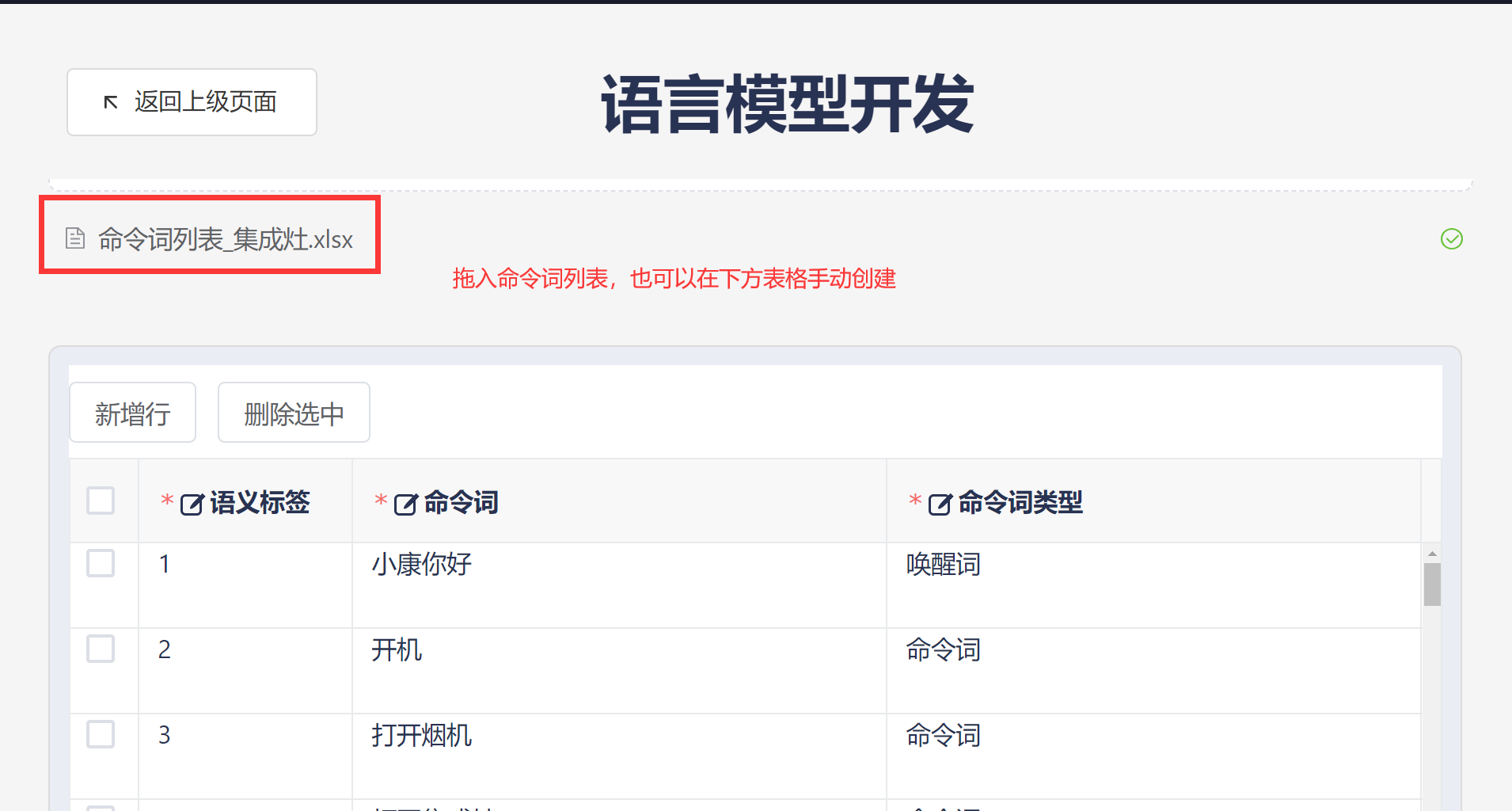
- 按照如下步骤进行模型制作:
1、填写语言模型信息;
2、选择上传命令词列表文件;
3、会自动进行命令词列表文件检查,并将命令词列表展示与命令词信息中,用户可以检查和修改;
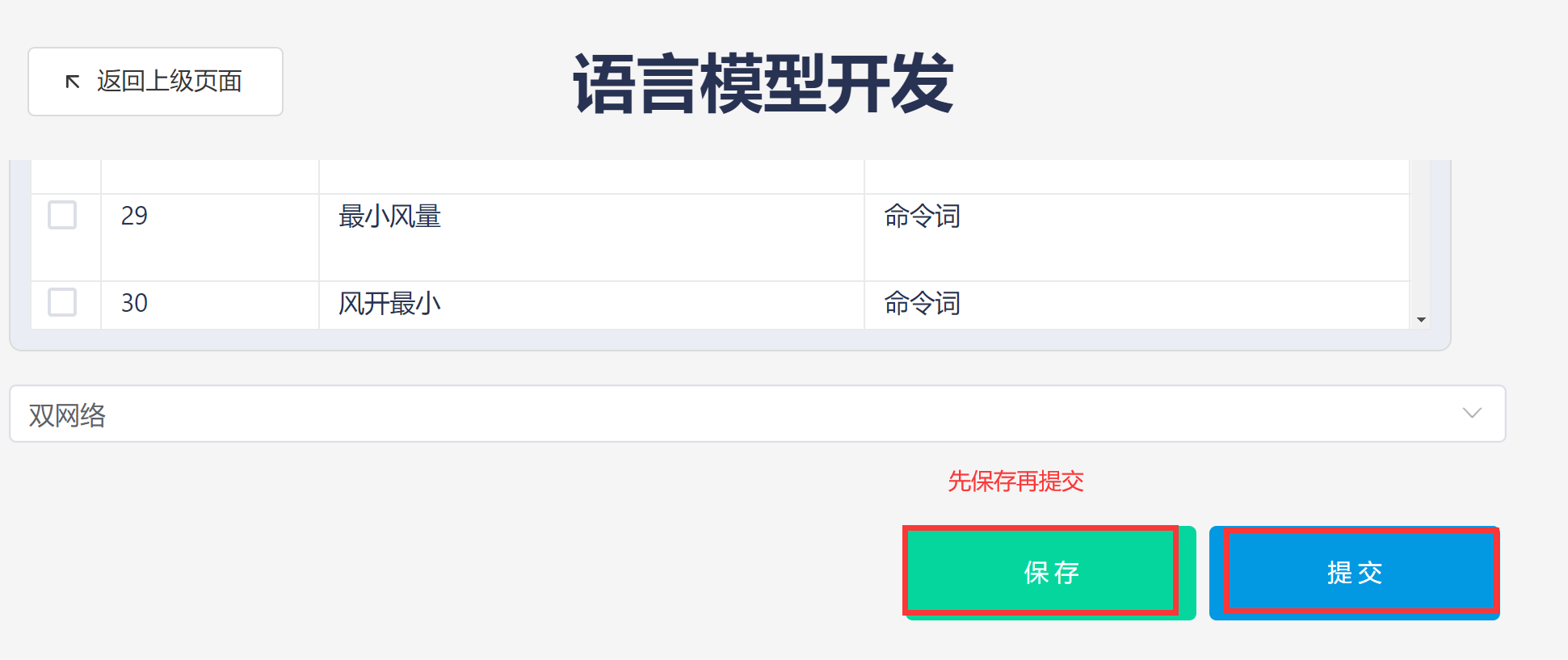
4、点击保存,平台开始制作模型;
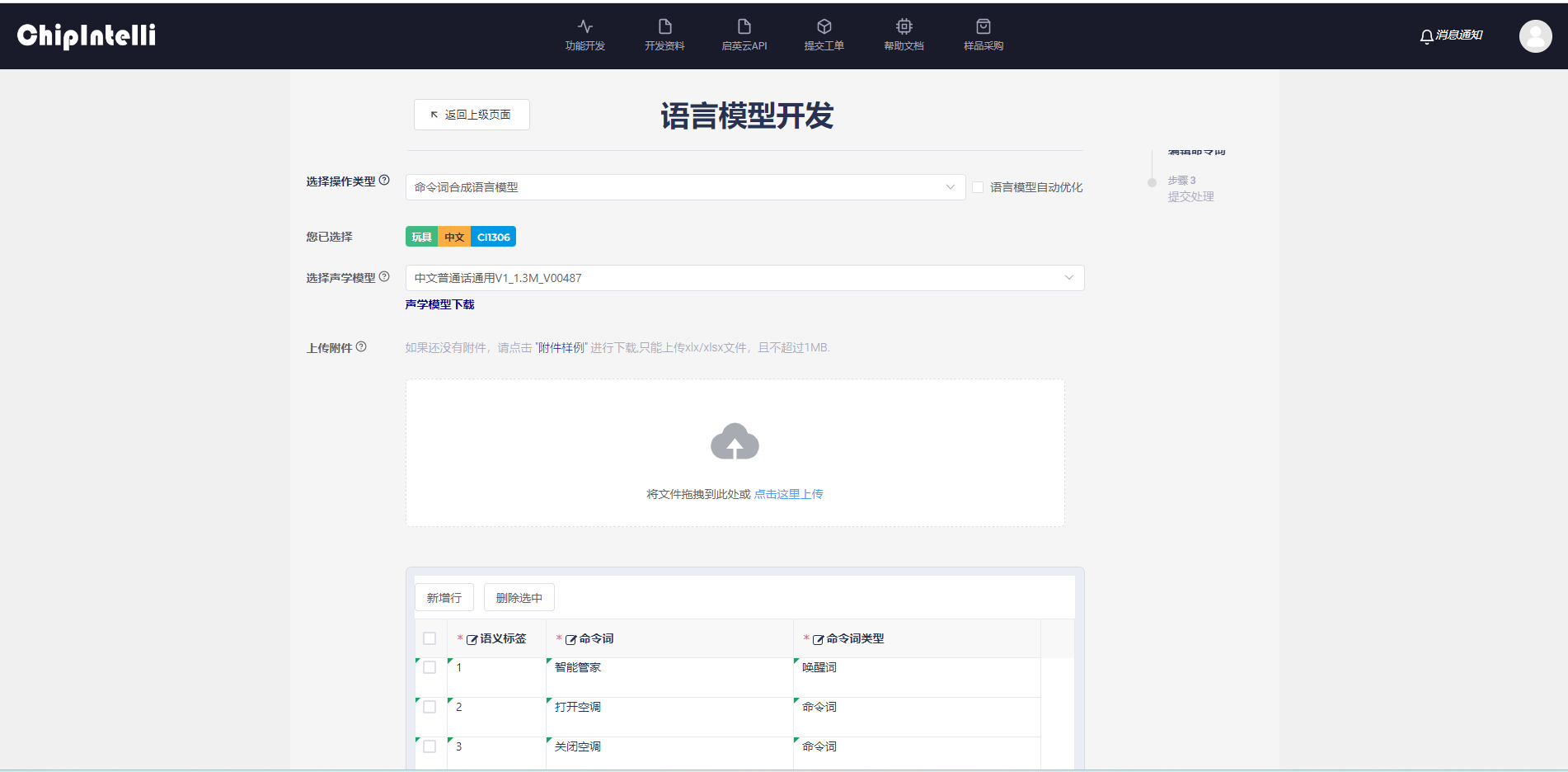
- 上述步骤中的上传命令词列表文件可以省略,直接在命令词信息表中通过“添加明细行”添加命令词,然后点击“生成语言模型(以网页表格内容为准)”,同样可以进行模型制作:
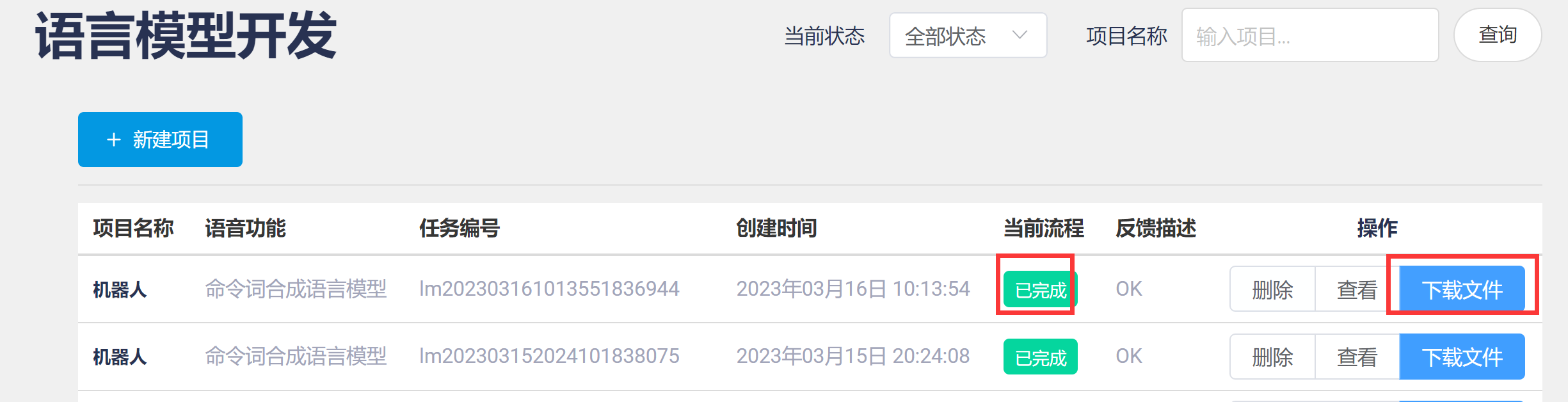
- 后台制作语言模型结束后,可以在下载窗口下载:
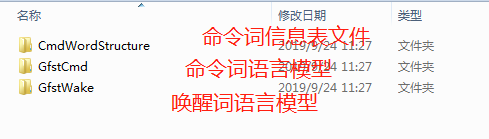
- 解压下载的语言模型压缩包,可以得到命令词信息表文件:”[60000]{xxxx}.xls” 和命令词、唤醒词语言模型文件 “asr_zn_xxx_xxx.dat”:
3. 生成播报音(voice)¶
- 从平台主菜单进入“播报音合成”界面:
- 创建项目:
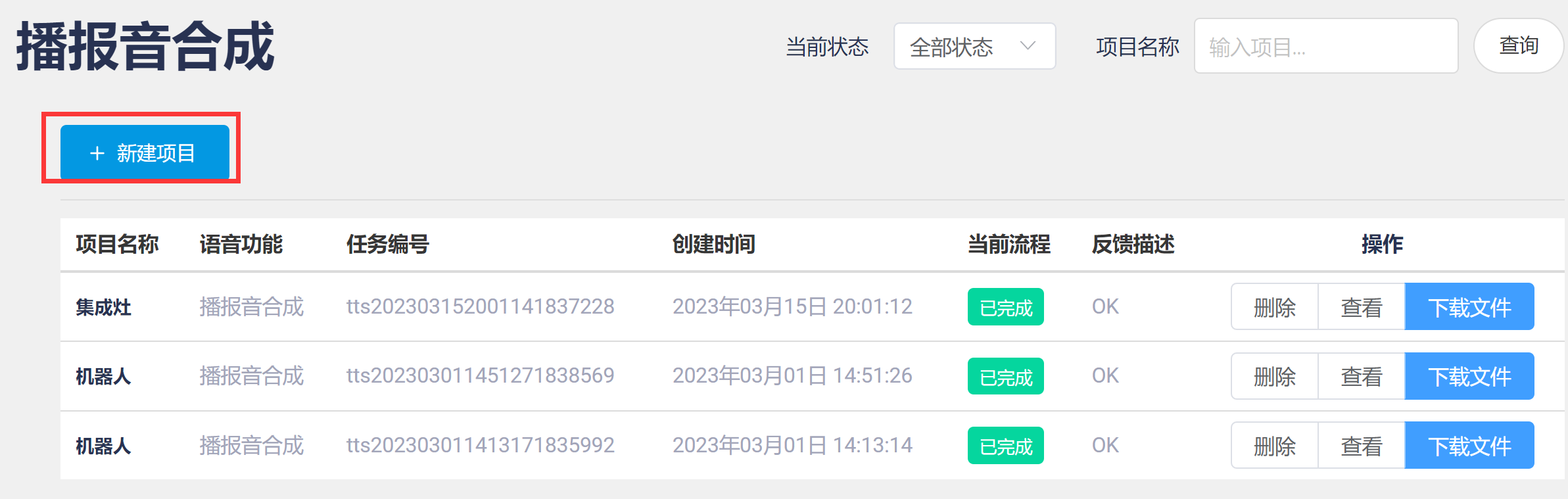
- 下载样例文件:
1、语言类型:下拉框选择中文、英文。
2、下载样例:根据语言类型选择,会出现中文、英文样例。
3、人声分类、合成人声:选择分类和人声后,可以试听样音,声音大小根据需求设置。
4、试听样音:点击后可以播放音频。
- 打开下载的模板文件,中文、英文示例如下:
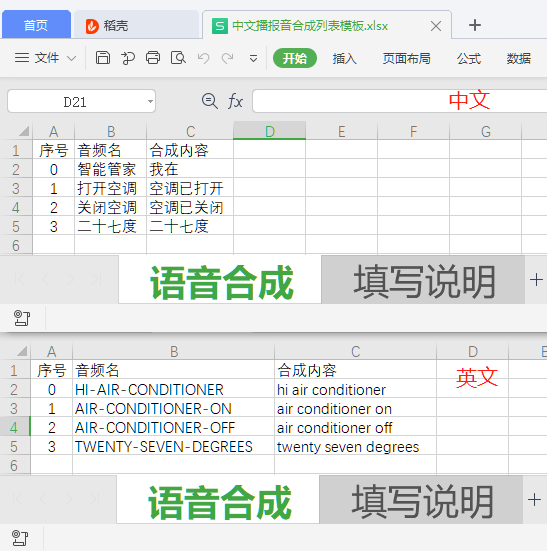
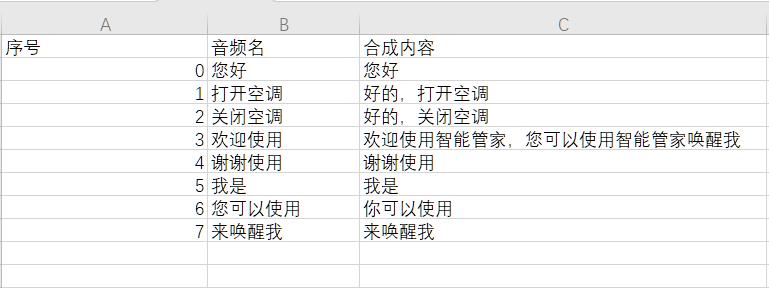
- 按照模板格式,编辑需要生成的播报音:
注解
- 音频序号:指定生成音频文件的ID号。
- 音频名:指定生成音频文件的文件名。
- 合成内容:语音内容(文字间,可以有逗号分隔符号,但不能有空格)
提示
制作播报音也有一些规则可以减小固件大小,节省FLASH空间。SDK支持组合播报和选择播报,就可以把某些具有共性的词提取出来,制作成一个音频文件。比如,打开空间,打开电视,打开风扇,打开台灯,打开客厅灯,打开书房灯,这么多词都有“打开”一词,就可把“打开”做成一个单独的文件,在命令词信息表文件中,用组合播报的方式关联到命令词。再比如一些可以更换名字的项目,上电播报可能是“我是xxx, 你可以使用xxx来唤醒我”,可以把这名话拆分成4个音频:
- 我是
- xxx
- 你可以使用
- 来唤醒我
在命令词信息表中关联播报音ID时填入”1+2+3+2+4”。
其中”xxx”可以是多个名字,通过组合加选择播报的功能,在程序中根据情况选择播报,就不需要为每个名字生成一套播报音了。
- 添加播报音文件,也可以在播报音合成界面表个白中实时编辑,然后保存提交。
- 等页面提示生成成功,出现“下载文件”按钮,点击即可下载:
- 下载得到下列音频文件:

4. 制作固件¶
4.1. 编辑命令词信息表文件¶
将2.2节下载得到的命令词信息表文件:”[60000]{xxxx}.xls”拷贝到路径:%SDK_PATH%\projects\cias_aiot_audio\firmware\user_file\cmd_info\,替换原始[60000]开头的文件,并按照项目逻辑做相关修改,主要是关联播报音,设置唤醒词,调整识别灵敏度等。

注解
- 模型名:用于设置当前这套命令词对应的模型名称,目前就2个:NN ID(声学模型文件ID)、ASR ID(语言模型文件ID)。
- 模型ID:用于设置当前这套命令词对应的模型ID号。填写0及大于0的数字均可,但需与文件前缀[ID]号匹配。例如,[3]asr_xxx_cmd.dat文件标识ID为3,ASR ID的模型ID就填3。
- 命令词:命令词字符串。
- 命令词ID:开发者自定义的命令词ID ,方便快速开发实现逻辑。默认不支持不同命令词使用相同的命令词ID,如果一定要可以修改脚本文件“cmd_info.bat”,cmd_info.exe 命令后添加“- -no-cmd-id-duplicate-check”。
- 命令词语义ID:语义ID,启英泰伦自定义的字符串语义ID,具有唯一性,如果产品考虑家庭组网的话,可以用此ID解决多个设备的命令词冲突问题。
- 置信度:用于调整命令词的识别灵敏度,解决误识别等。
- 唤醒词:用于指定唤醒词。
- 组合词:用于指定组合词,既是唤醒词,又是命令词,少了唤醒一步。
- 期望词:用在某些命令词特别不容易识别时使用。
- 不期望词:用在某些命令词特别容易识别,而不能识别另外一个相似的正确命令词,导致误识别。
- 特殊词计数:用于短的命令词截获具有相同内容的长命令词的情况。比如:“加热”和“加热三分钟”,可能说“加热三分钟”,也会得到“加热”的结果。解决方法是给“加热”命令词设置特殊词计数,在识别到“加热”后,再等待一会,看后续是否有相近命令结果,如果有就丢弃“加热”。也不能设置的太大,否则会明显增大“加热”的响应时间。
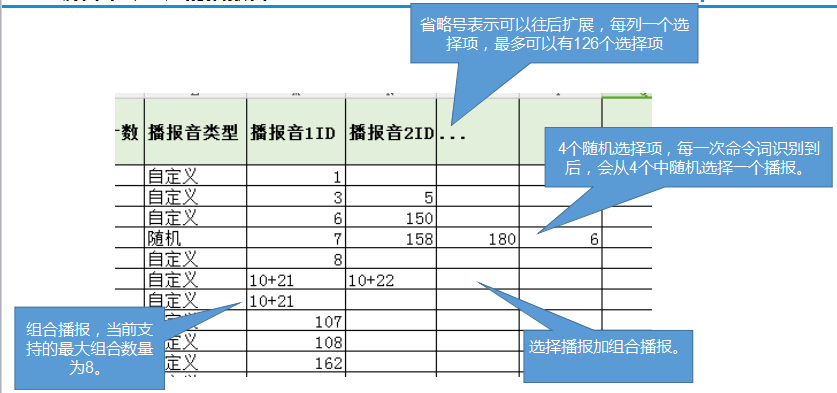
- 播报音类型:主要用于多个选择播报时,指定选择的方式。当前支持两种,“随机选择”(调用播报接口时,select_index设置为-1),“自定义选择”(调用播报接口时,select_index设置为要选择的值)。
- 播报音ID:播报音文件ID(也就是第4章中的音频序号),组合播报用‘+’连接(最多支持16个音频组合),如果有多个选择播报,每个选择项占一列,最多127列。
- 模型分组ID:用于多模型切换。SDK demo中默认0为命令词模型,1为唤醒词模型。
提示
- 如果有未关联到命令词的播报,可以创建一个假命令词,也就是命令词字符串未用于生成语言模型,不会被识别到,但可以通过些字符串播放出来。
- 编辑命令词信息表文件名的ID必需为60000,不能修改,如[60000]{xxxx}.xls。
- 注意适当应用组合播报,选择播报,多模型切换功能,可以减小固件大小,节省FLASH空间。
4.2. 编辑代码,实现项目需求¶
- 用户逻辑的实现主要在“system_msg_deal.c”文件中;
- UserTaskManageProcess函数就是用户逻辑处理任务,在这个任务里处理各种消息,如:语音识别消息,按键消息,串口消息等。
- 找到要处理的消息,实现对应的逻辑功能。比如IO控制,播报音选择,切换模型,参数调整,串口上报等。
- 如果有需要关机保存的信息,可以使用ci_nvdm模块保存,请参考SDK中标准demo中音量设置相关代码。
注解
- 如果有用命令词切换模型的,同时切换模型的命令有语音播报,注意切换模型接口与语音播报的调用顺序,需要根据播报音所在的模型来定。
4.3. 合成并烧录固件¶
4.3.1. 拷贝资源文件¶
固件制作目录如下图:
- 将第2章节生成的语言模型文件(asr_zn_214_CI130x.dat)放入firmware目录下的asr目录中, 按照4.1节编辑的《命令词信息表》中ASR ID设置文件ID号,如[0]asr_zn_214_CI130x.dat。如果使用双网络,需将唤醒词、命令词的语言模型均放到该目录;
- 将第2章节生成的声学模型文件GE-CH-S-V00214.fefixbin3676,放入firmware目录下的dnn目录中,设置按照4.1节编辑的《命令词信息表》中NN ID设置文件ID号,如[0]GE-CH-S-V00214.fefixbin3676。如果NN目录下已有该模型,无需再替换;
- 将第3章节生成的播报音文件(TTS_wav目录下的wav格式的音频文件)放入firmware目录下的voice目录中,按照4.1节编辑的《命令词信息表》中VOICE GROUP设置文件夹ID号,如[0]voice。
- 编译工程代码,生成user_code.bin,在user_code目录下;
- 合成分区bin文件,双击运行”合成分区bin文件.bat”,完成后,会在asr、dnn、user_file、voice目录下生成与目录同名的bin文件。
4.3.2. 语音固件打包烧录¶
- 语音固件打包烧录固件参照☞开发环境搭建与使用-6章节