单麦语音识别项目开发-CI13162¶
一. 准备工作¶
1.1 硬件准备¶
开发模块:启英泰伦 CI13162模块板 (推荐型号 CI-F162GS02J)
烧录工具:USB转TTL串口调试工具(可5V供电)
麦克风、喇叭:启英商城购买麦克风、喇叭与模块板匹配,批量购买具体参数可参考:麦克风兼容列表
测试设备:个人电脑(建议Windows 7及以上系统)
1.2 软件准备¶
启英泰伦环境:Visual Studio Code
开发框架:CI13LC_SDK_ASR_Offline_V2.0.15(若有新版本,请使用最新版本的SDK)
1.3 资料获取¶
官方资源
二. 软件配置¶
2.1 开发环境搭建¶
1.下载安装Visual Studio Code
2.下载相关SDK,通过VS Code打开
3.安装编译插件,安装gcc编译工具链,可以输出code.bin文件用于固件生成
具体流程可以查看:编译软件安装与使用
2.2 开发工具配置¶
烧录工具
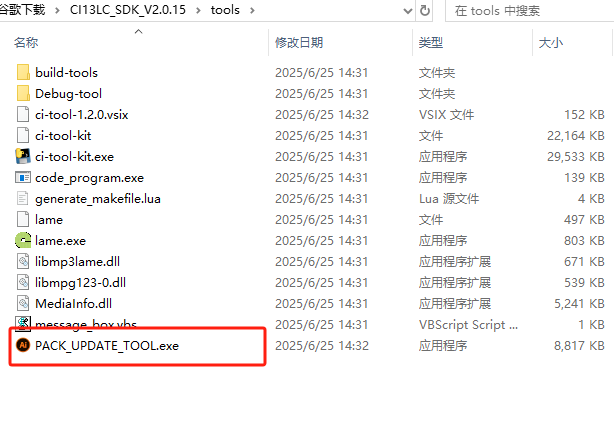
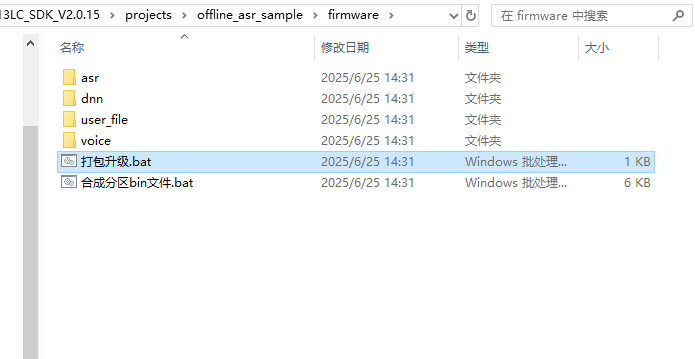
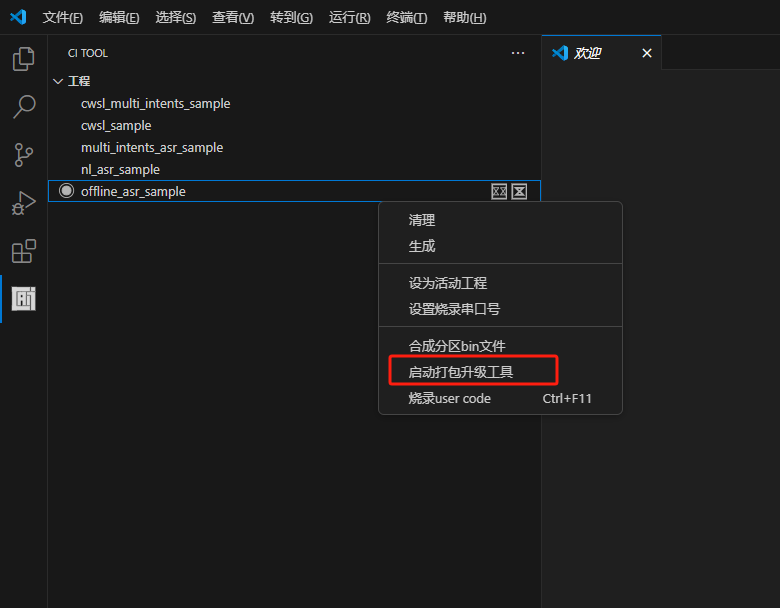
PACK_UPDATE_TOOL.exe,位置在SDK根目录下的tools文件夹中,也可使用Firmware文件夹下的”打包升级.bat”和sdk编译界面右键”启动打包工具”打开,使用方式在2.1的资料中可以学习,也可以在3.2下载的模块设计资料中的”启英泰伦-固件升级&打印操作说明文档”查看。
测试工具
市面上串口调试上位机都可以,一般通信波特率9600,与电脑通信测试语音模块识别和播报功能。下载和使用方式可以参考:UART串口调试工具使用说明。
三. 硬件开发¶
3.1 CI-F162GS02J 模块特性¶
芯片参数
CI-F162GS02J 模块搭载CI13162芯片,该芯片集成了启英泰伦自研的脑神经网络处理器BNPU V3.5和CPU内核,系统主频可达210MHz,内置高达288KByte的SRAM,2M的Flash,集成PMU电源管理单元和RC振荡器,集成单通道高性能低功耗Audio Codec和多路UART、IIC、IIS、PWM、GPIO、PDM等外围控制接口。芯片仅需少量电阻电容等外围器件就可以实现各类智能语音产品硬件方案,性价比极高。
接口资源
模块体积小巧,长宽为30mm×40mm,工作电压为3.6V-5.5V,板载功放,带一路麦克风、一路喇叭和一路5V电源及UART的接口,模块插入麦克风和喇叭直接供电即可使用,也可以直接通过接插件将UART连接到产品主控板,由产品主控板的5V电源进行供电,UART通信或GPIO控制,无需焊接。模块包含2个3.5mm螺丝孔,方便固定及安装。
更详细信息可以通过1.3中资料查看。
3.2 外围电路设计¶
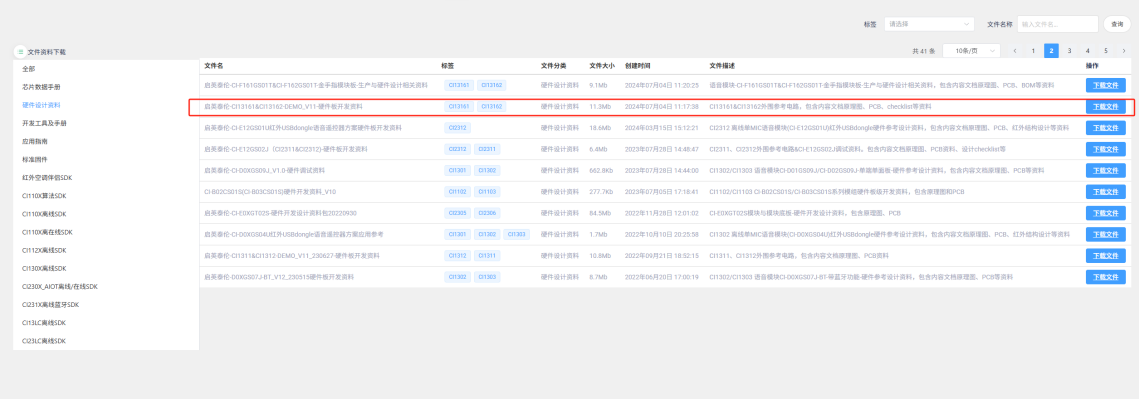
详细资料可以点击硬件设计资料下载,这里不具体介绍,有pdf版本原理图,PCB查看需要自行下载AD等专业软件。资料中的”硬件调试相关说明文档”内包含硬件调试与问题查找,可以提供许多帮助。
四. 软件开发¶
4.1 固件开发方式¶
一般来说程序部分需要改动部分只包含:串口通讯协议、命令词ID或语义ID判断处理、芯片版型等基础宏定义,这些内容在启英泰伦语音AI平台的”离线语音识别大模型应用”中已经做成可以填写表格或数值与开关来设置,自动生成对应的固件与可修改的SDK。以下用图文描述如何使用平台制作基础固件以及用SDK和命令词表合成固件两种方式。
想了解整体程序结构介绍可以参考:SDK软件结构。
平台制作固件流程也有视频可供学习:视频教程。
基于平台制作基础固件
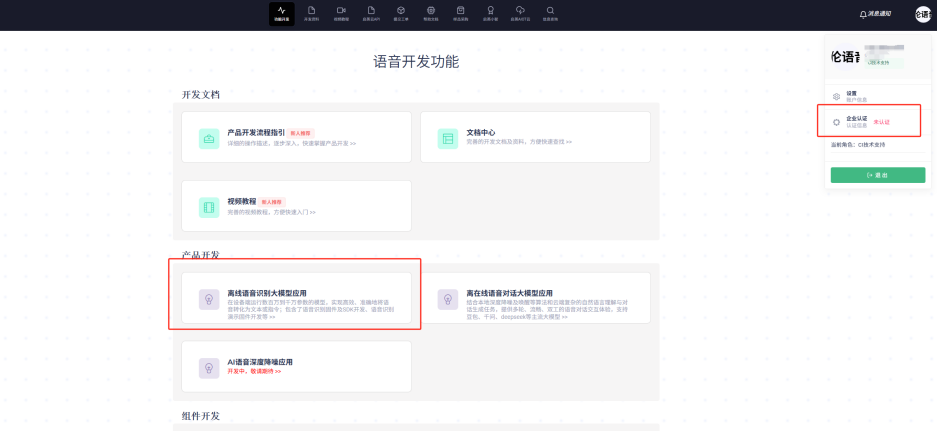
首先点击进入”离线语音识别大模型应用”。需要注意的是,使用平台制作固件建议再右上角先进行公司认证,这样可以体验更多高级优化功能。
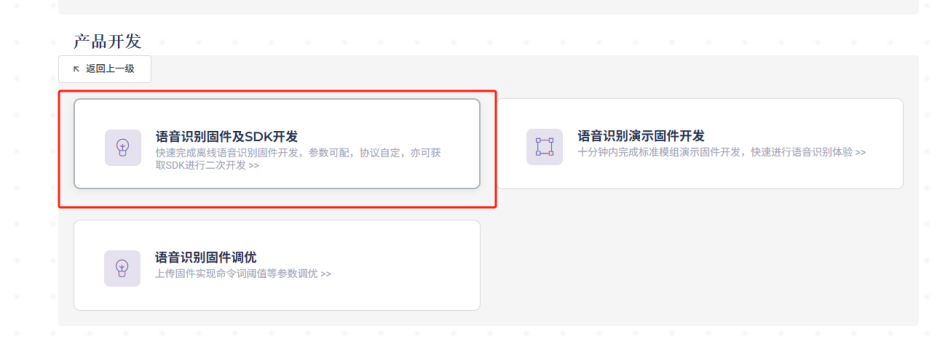
点击”语音识别固件及SDK开发”
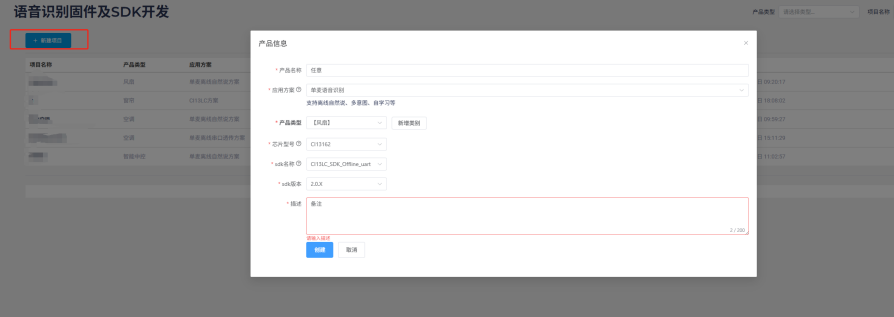
新建项目,”产品名称”和”描述”可以根据需要填写,”应用方案”选择单麦语音识别,”产品类型”与需要实际一致,主要影响后续领域识别模型选择,”芯片型号”选择13162后另外都为唯一选项,若后续有更新版本可以选择新版本。
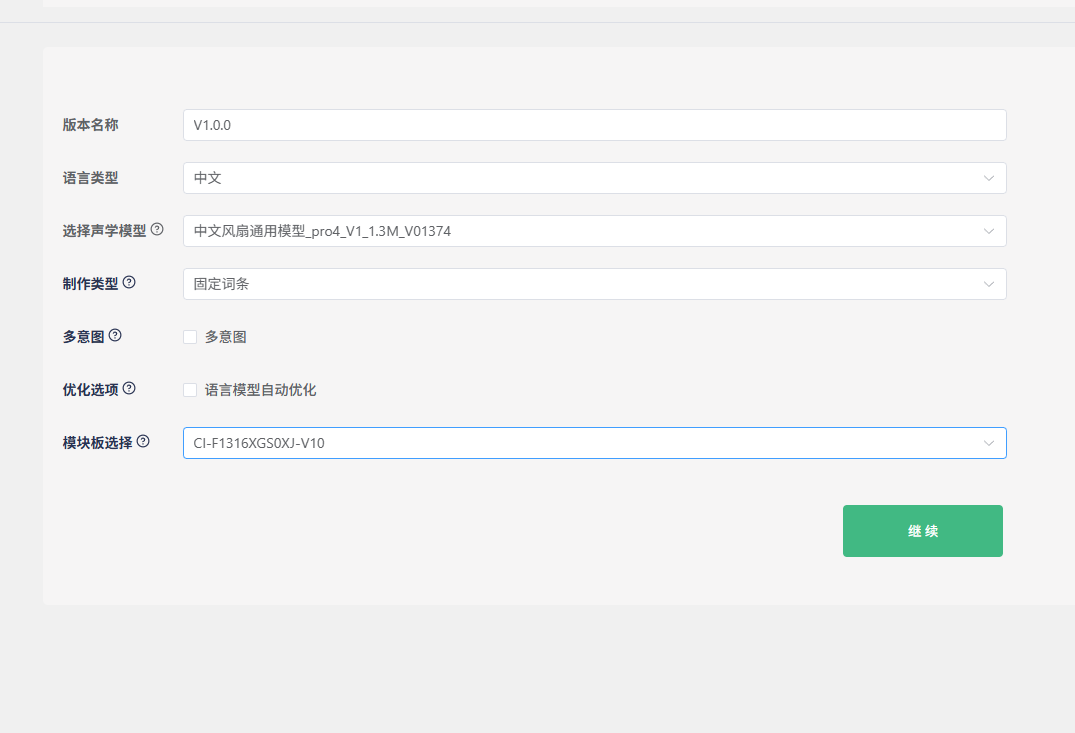
“版本名称”默认不改,”语言类型”以中文为例,”选择声学模型”比较重要,它影响了在实际环境中的降噪效果和对一些命令词的反应灵敏度,选择标准是在实际产品领域越新越大效果越好,以上图为例,pro4是模型版本,目前为最新,1.3M是模型大小,是目前13162能容纳的最大模型大小,1374是模型编号,作用是区分模型。”制作类型”可以选择固定词条与自然说,我们这里选择固定词条演示。”优化选项”默认勾选,如果后续要制作自然说或者改其他语种制作命令词可以不选加快SDK制作。
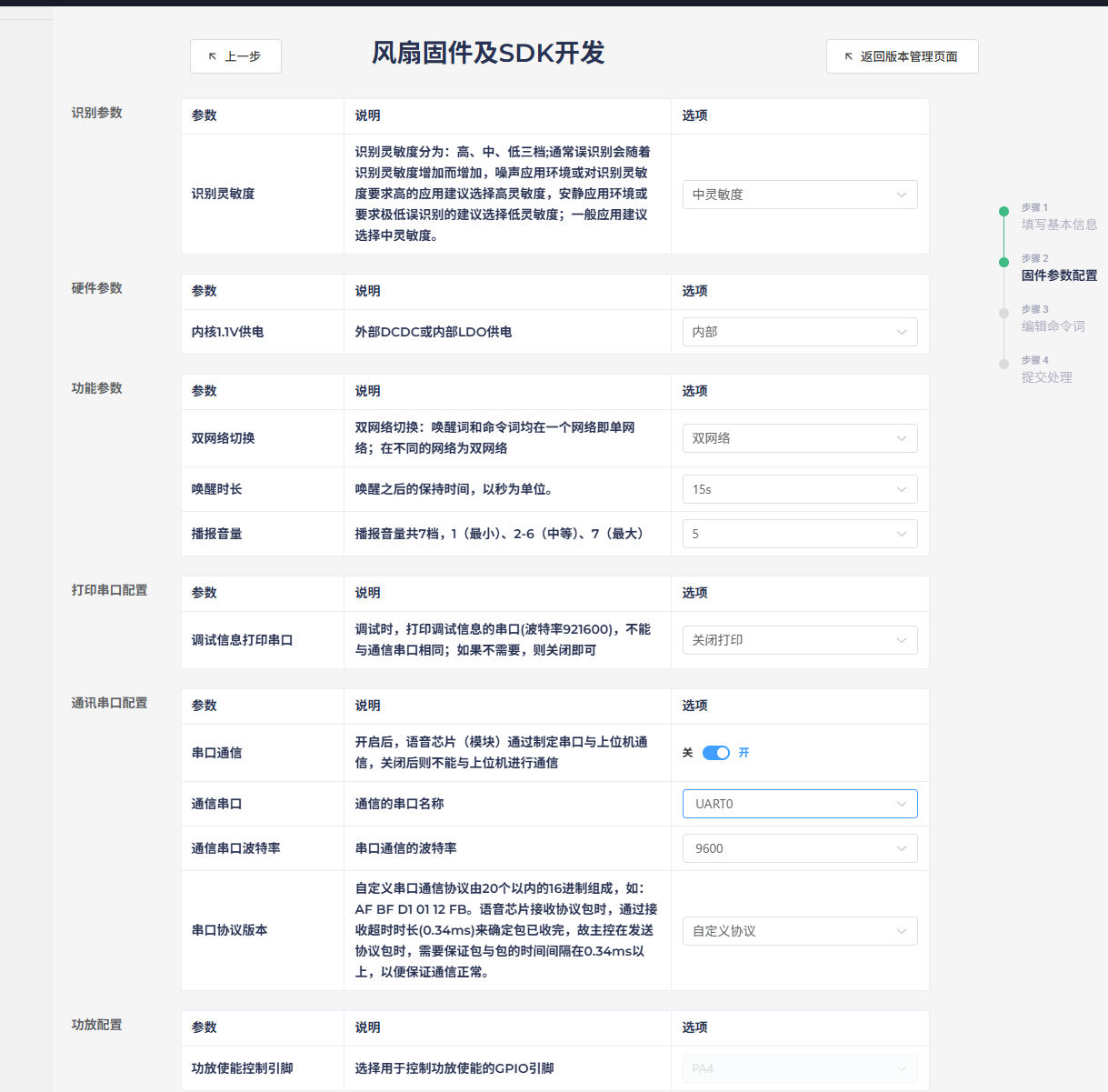
灵敏度可以选择中或者高,后续可以自己调整,供电选项默认,网络切换一般选择双网络,有唤醒词可以更好减少误触发。唤醒时长和初始音量根据自己需要修改,打印串口因为模块只有一个串口0可以对外通讯,所以要改为其他选项。通讯串口选择串口0,波特率也根据实际修改,串口协议只能自定义,后续需要自己填写。功放配置不变,点击继续。
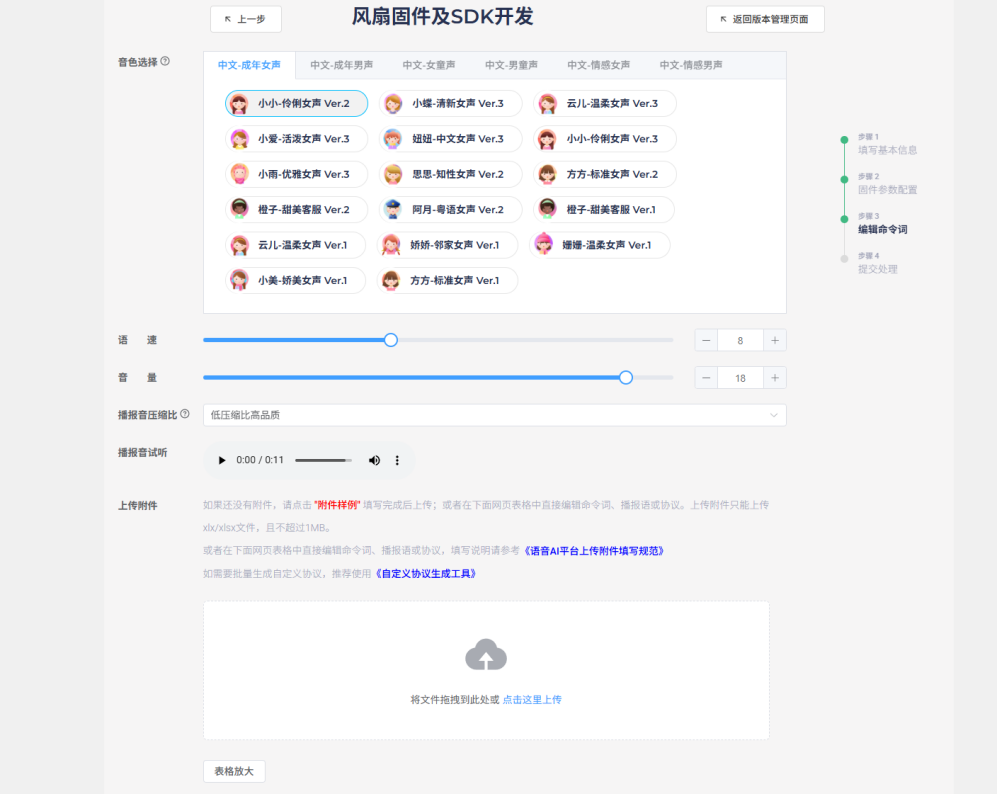
播报音的音色、语速、音量都可以根据自己想要的修改,压缩比可以优先选择低压缩比,音质质量高。点击”附件样例”下载命令词表格。
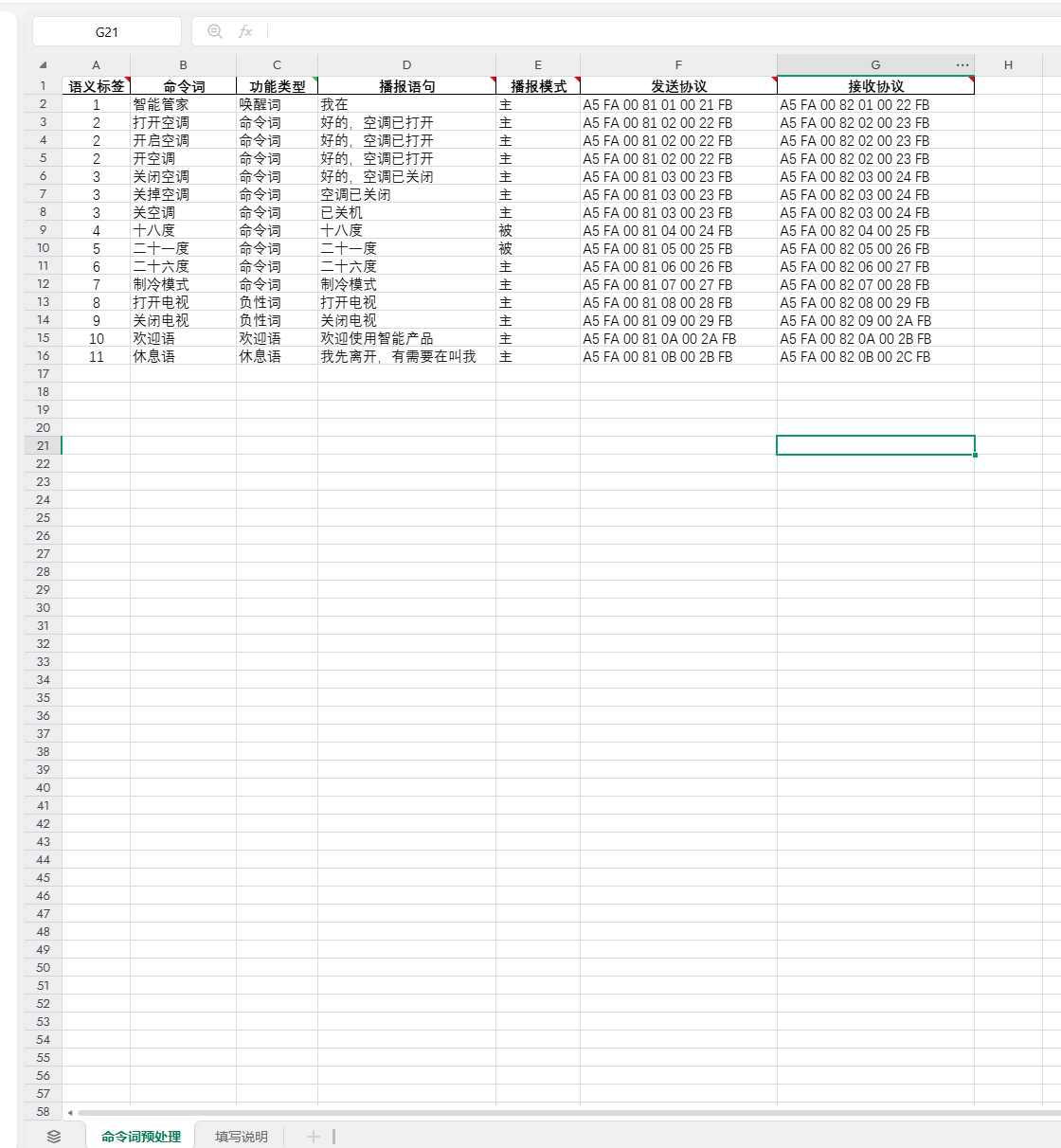
用下载的样例来说明,第一列语义标签用来区分每个词条,避免相互冲突。
第二、三列“智能管家”是唯一的唤醒词,它的作用是在平时不使用的时候阻挡误触发,只有说了这个唤醒词之后,在15秒的唤醒时长里再说其他命令词才会起效,触发命令词则继续延长15秒唤醒,否则就又需要先触发唤醒词。命令词则是可以对外进行控制的指令,根据产品不同选择不同指令。”打开电视”和”关闭电视”作为负性词,用来减少唤醒之后对”打开空调”等指令的误触发,可以自行增减,欢迎语是上电播报的内容,用来引导用户使用,休息语是15秒不使用后的退出提醒。以上词条触发后都会从串口0发送对应的协议,可以不填协议,则不会发送数据。除此之外,第三列还有”增大音量”“减少音量”、”最大音量”、”最小音量”、”开播报”、”关播报”功能,顾名思义,触发后可以控制语音模块相应功能,可以自行尝试填写。
第四列播报语句是第三列对应的反馈声音,根据第五列的主动被动类型决定是否需要第七列电脑或者电控发送对应接收协议才能播报。
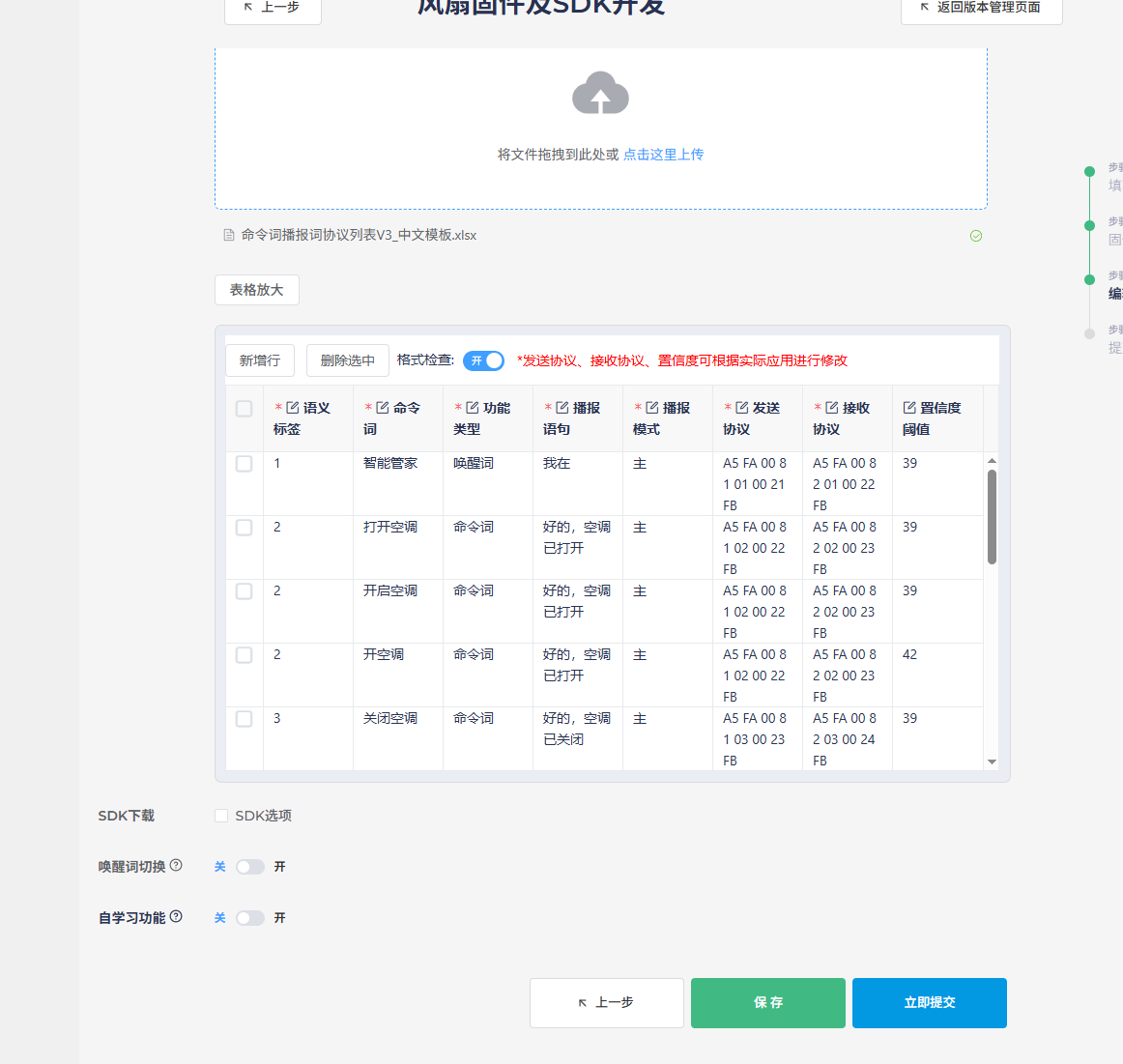
填写好表格之后在制作界面点击上传,表格就会加载进去,注意中文命令词不能出现英文词汇、空格、标点符号等,否则格式检查不通过无法制作固件。
SDK下载选项建议勾选,后续有需要修改程序逻辑可以直接在下载的SDK中修改,唤醒词切换等功能根据实际需要制作,这里不做具体描述。点击立即提交之后,等待一定时间,固件和SDK即可下载测试。
基于SDK制作基础固件
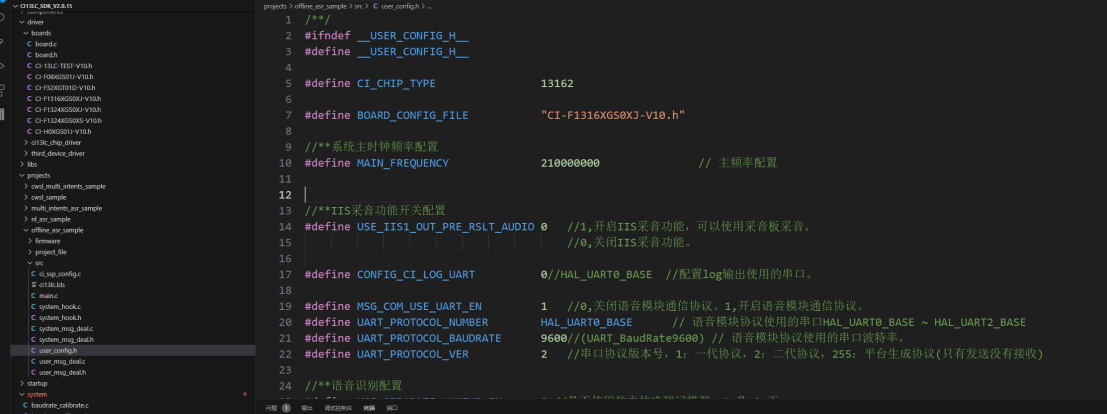
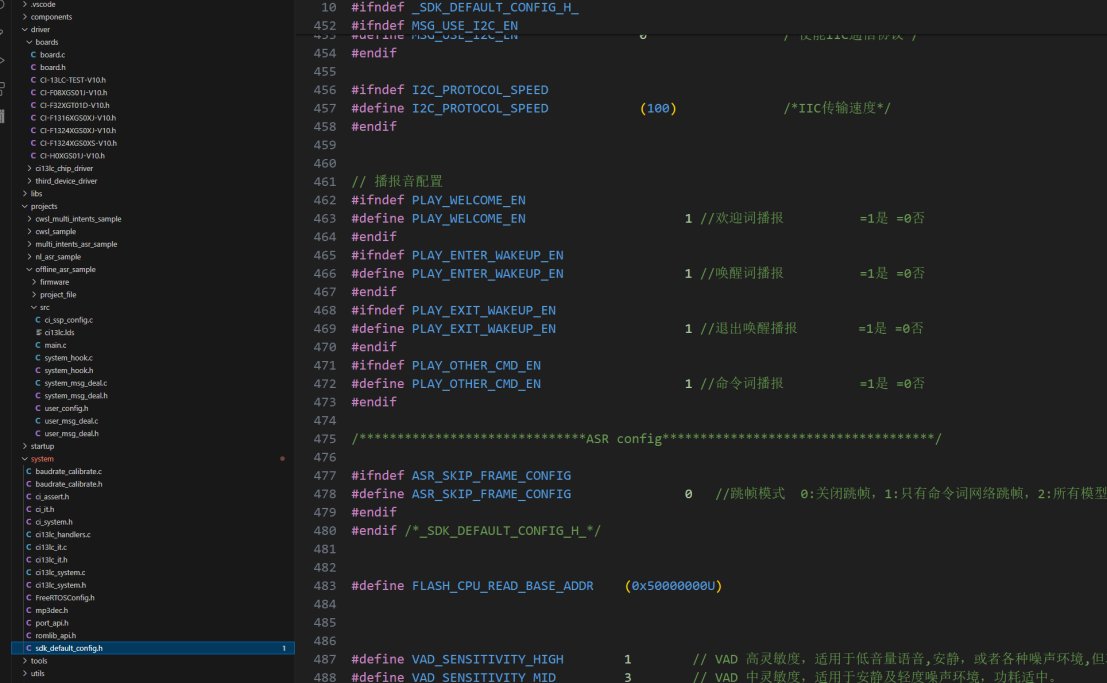
首先根据2.1的步骤安装好开发环境后打开SDK,在user_config.h和sdk_default_config.h中设置好芯片型号、版型配置、串口配置、主被动播报等宏定义信息
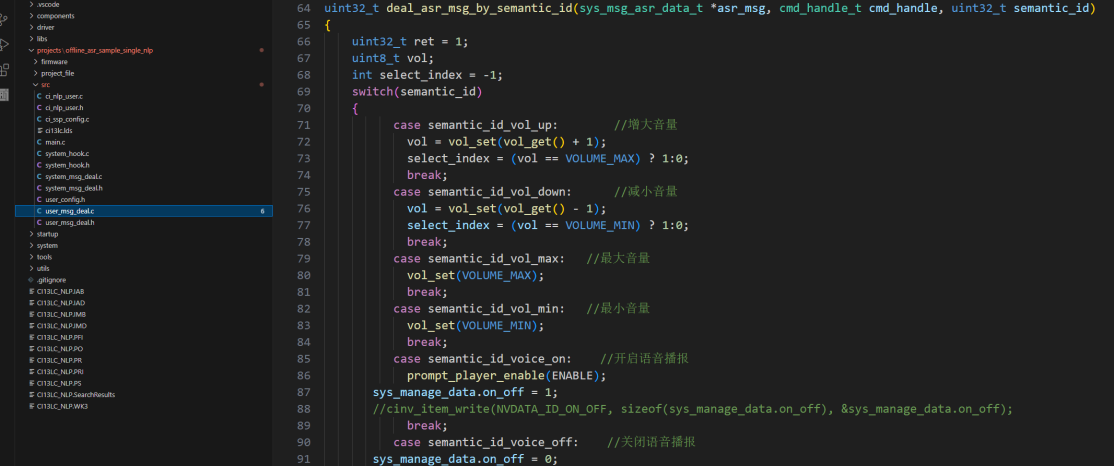
在deal_asr_msg_by_cmd_id或deal_asr_msg_by_semantic_id函数中配置音量变化等控制
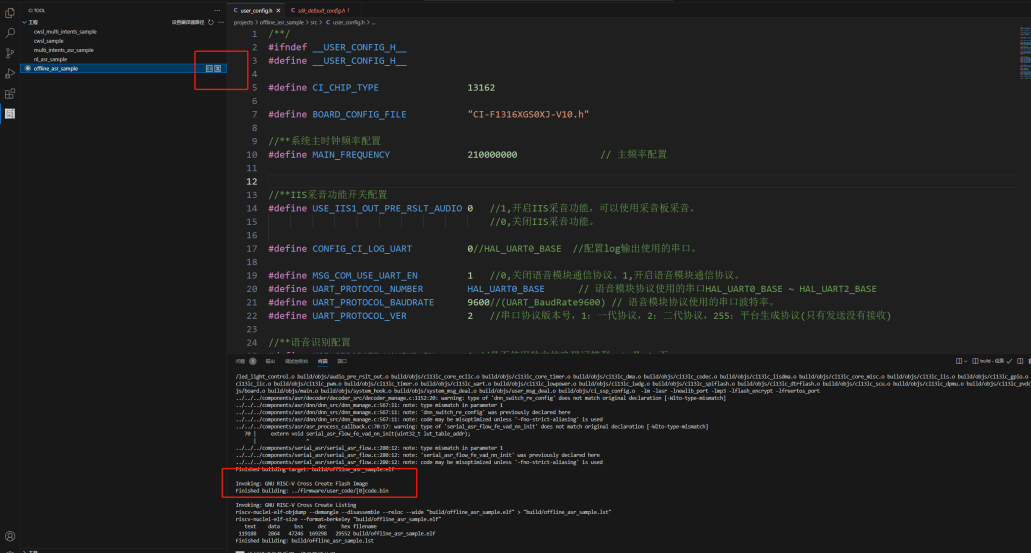
修改完代码后在左边工具栏切换工程编译,点击清理和生成即可合成修改后的code.bin。若有报错可以用ctrl+F查找对应错误位置进行修改。显示Finished building: ../firmware/user_code/[0]code.bin说明编译成功。
更多程序控制可以查看芯片驱动,在userapp_initial(用户初始化)等函数中进行调用。本SDK采用Free RTOS操作系统,运行软件定时器等深度编程请查看相关学习资料
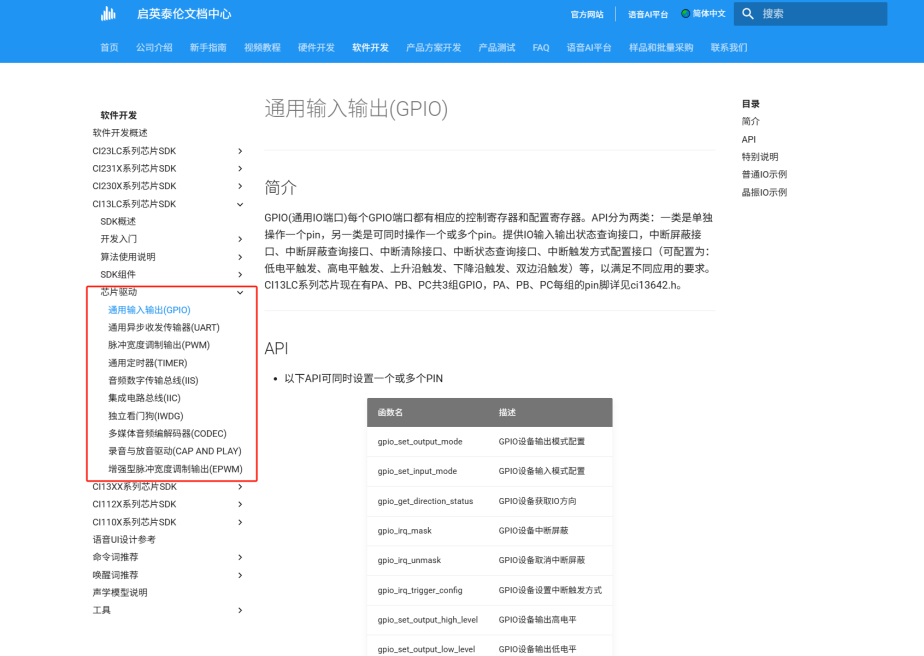
剩下的命令词、播报音、以及命令词信息表文件制作,还有后续的合成固件与下载,都可以查看链接:命令词和固件制作指南。
4.2 自学习、自然说与多意图方案¶
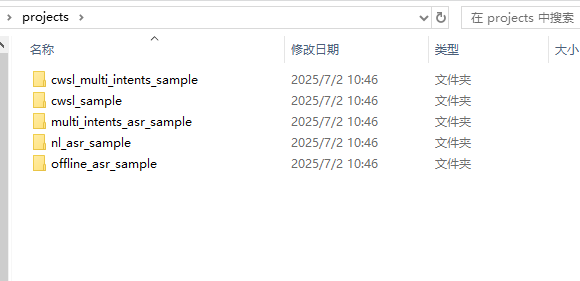
13162的SDK中有多个项目工程,可以对应开发多种方案,从上到下依次是自学习多意图方案、自学习方案、多意图方案、自然说方案、固定词条方案。下面介绍各个方案的应用与开发。
自学习方案
自学习方案可以在基础预设指令的基础上,通过学习唤醒词和命令词的方式进行功能绑定学习新的人声,从而兼容口音较重或咬字不清用户的声音,比如各地方言。
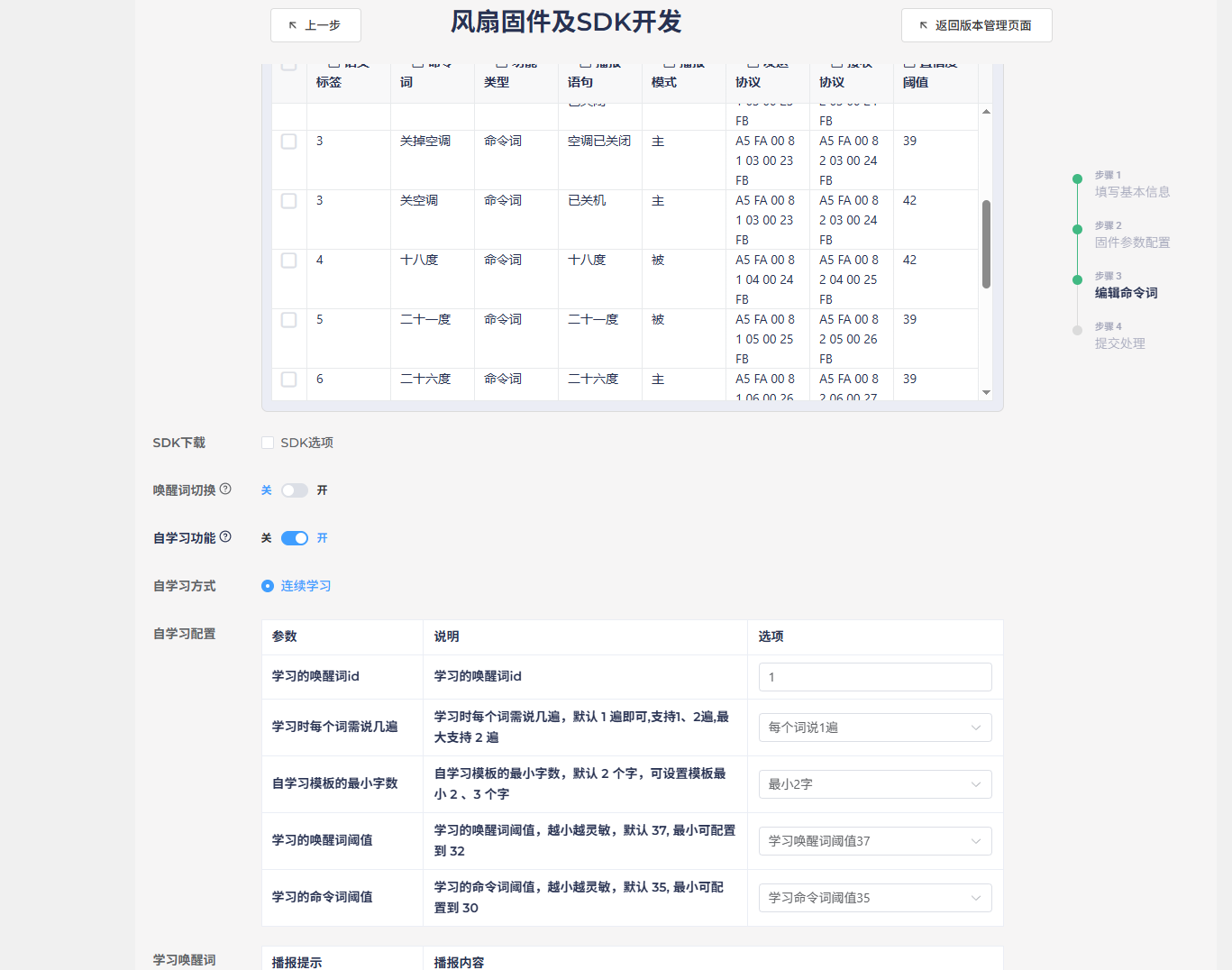
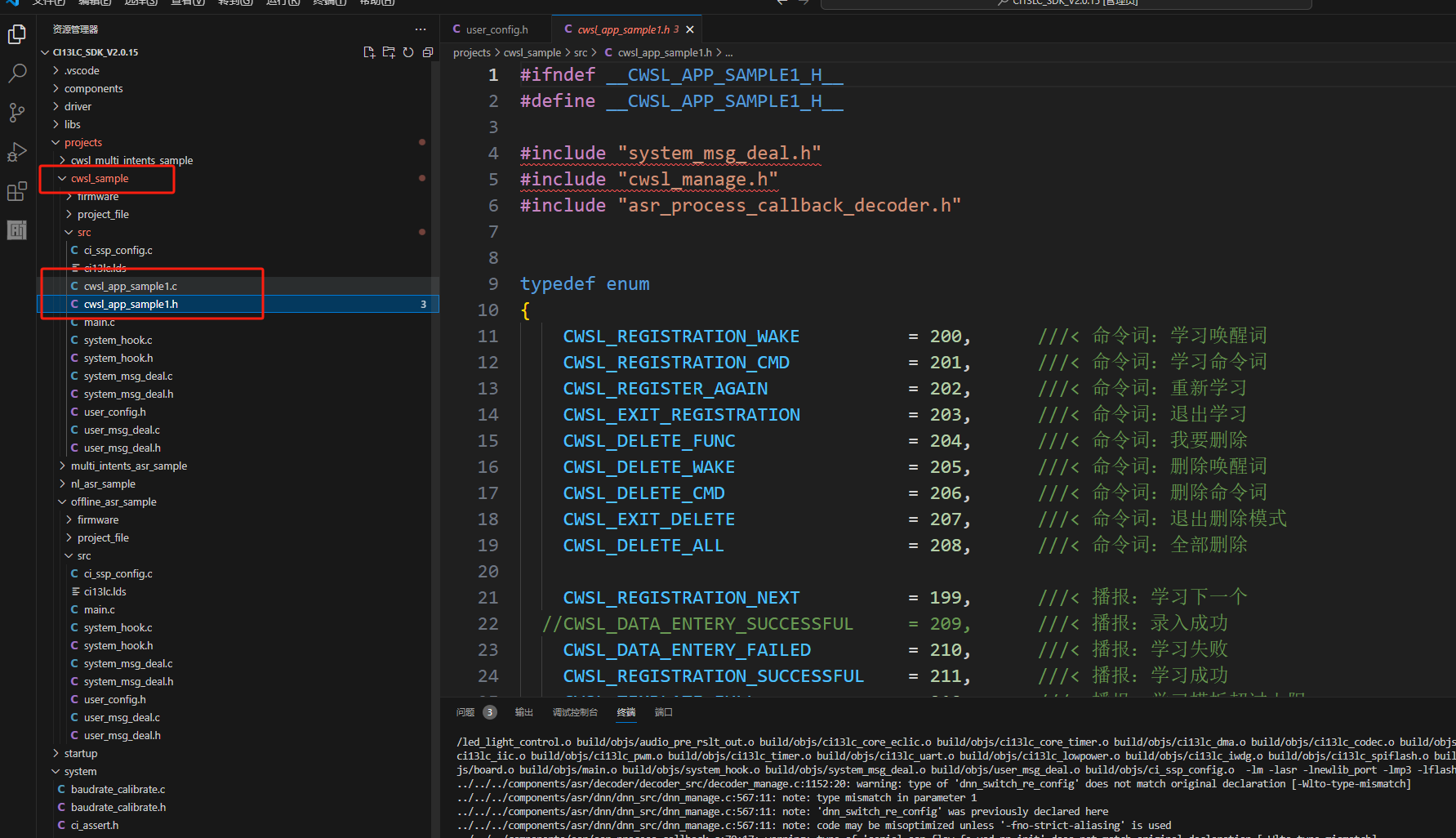
自学习的开发建议在4.1的基于平台制作基础固件最后开启自学习功能,只需根据提示填写内容即可生成对应功能,而在SDK程序中主要控制和修改部分则在projects\cwsl_sample\src\cwsl_app_sample1.c和cwsl_app_sample1.h,可以自行学习。详细开发资料可见离线命令词自学习使用说明
自然说方案
自然说方案,它比固定词条识别的说法更加广泛和自然,更贴近自然语音交互。SDK工程选择自然说工程,程序开发内容和固定词条没有多大变化,增加了相关算法,命令词制作建议单独从4.1最后资料中提到的”语言模型开发”入口,操作类型选择命令词合成模型,注意不要勾选后面的自动优化,模型类型选择自然数(推荐),就可以从下面的最小功能词推荐中勾选启英泰伦已经优化好的功能词条,每个功能对应都有许多自然说法。如果有其他功能,则需要另外上传命令词模版表格。
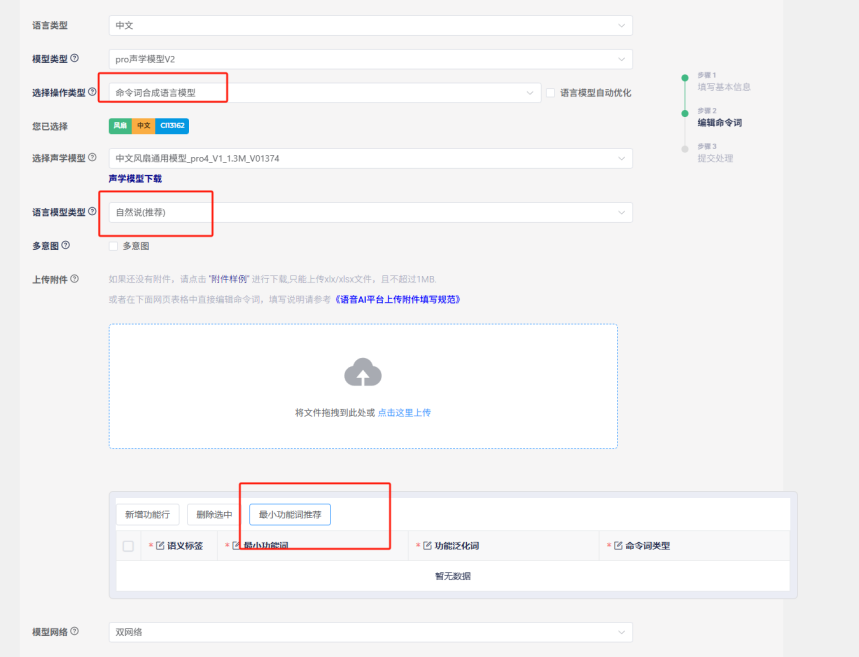
多意图自然说方案
多意图方案,它可以一句话说最多三条指令来进行识别控制,兼容自然说功能,命令词模型生成需在正常基础上勾选”多意图”,工程选择多意图工程,开发调试难度较大,具体学习资料可见离线自然说方案平台开发流程指引
五. 识别优化¶
5.1 声学模型选择与原理¶
降噪训练
在4.1选择声学模型时有提到需要选择对应产品描述的模型,这是因为我们的不同领域模型在训练时都会进行带上实际产品噪音训练,风扇、浴霸、烟机,不同产品在不同形态和功率下噪音各不相同,单纯以最高噪音的产品噪音去训练效果不一定好。
指令训练
各个产品的指令也各不相同,我们需要在不超过芯片内存大小的模型中放入所有指令的训练集可想而知是不现实的,因此将模型分成不同领域,将出现频率较高的词条训练集放入其中加强训练才是更好的选择。
如果产品比较小众,没有找到相应的领域模型,推测一下哪种领域噪音和词条更接近实际产品去选择声学模型可能是个比较好的选择。
5.2 语言模型优化¶
置信度与特殊词计数优化
命令词信息表[60000]{xxxx}.xls包含了置信度与特殊词计数,下图表格中第四列就是置信度,是指用户说的声音和训练的指令模型声音近似门槛值,超过这个值可以认为是识别成功,通过向上和向下调整这个值可以降低灵敏度减少误触发,或者提供灵敏度但是也会提高误触发几率,通过实际体验修改置信度达到一个平衡。
下图表格中第九列就是特殊词计数,通过提高它的数值可以增加前面命令词所需要算法判断超过置信度次数的值,这样可以减少长命令词被误识别成短命令词,比如”打开卫生间灯”误识别成”打开灯”,就需要增加”打开灯”的特殊词计数。
注意,修改完命令词信息表等需要重新点击”合成分区bin文件.bat”,否则打包的新固件依然是之前的内容。
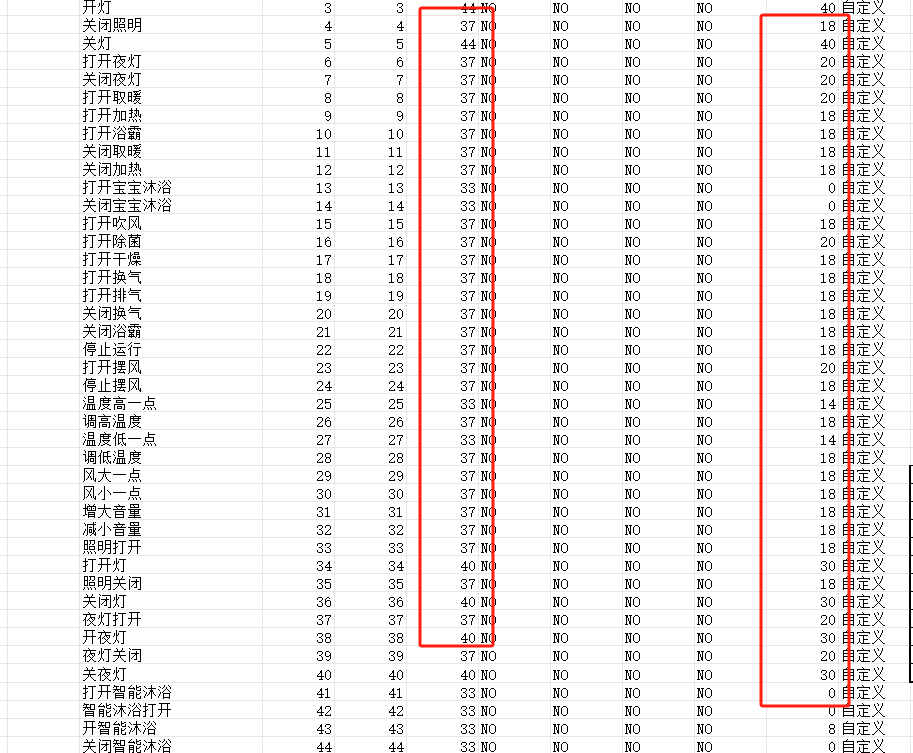
分词优化
在平台下载的压缩包中GfstCmd和GfstWake文件夹中都有相应的语言模型和对应的分词文件,用Notepad++打开分词文件可以修改一些内容来调整识别权重
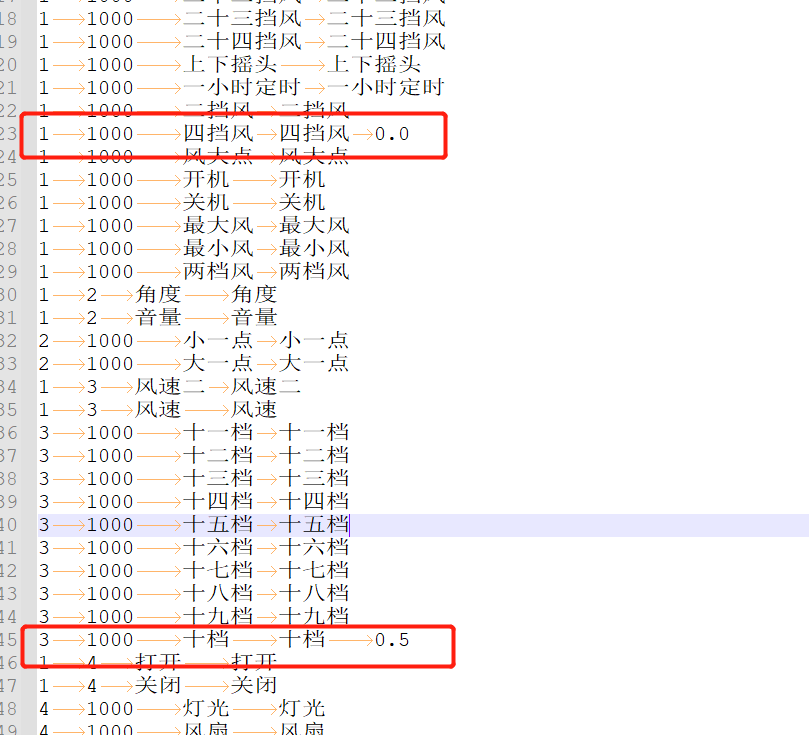
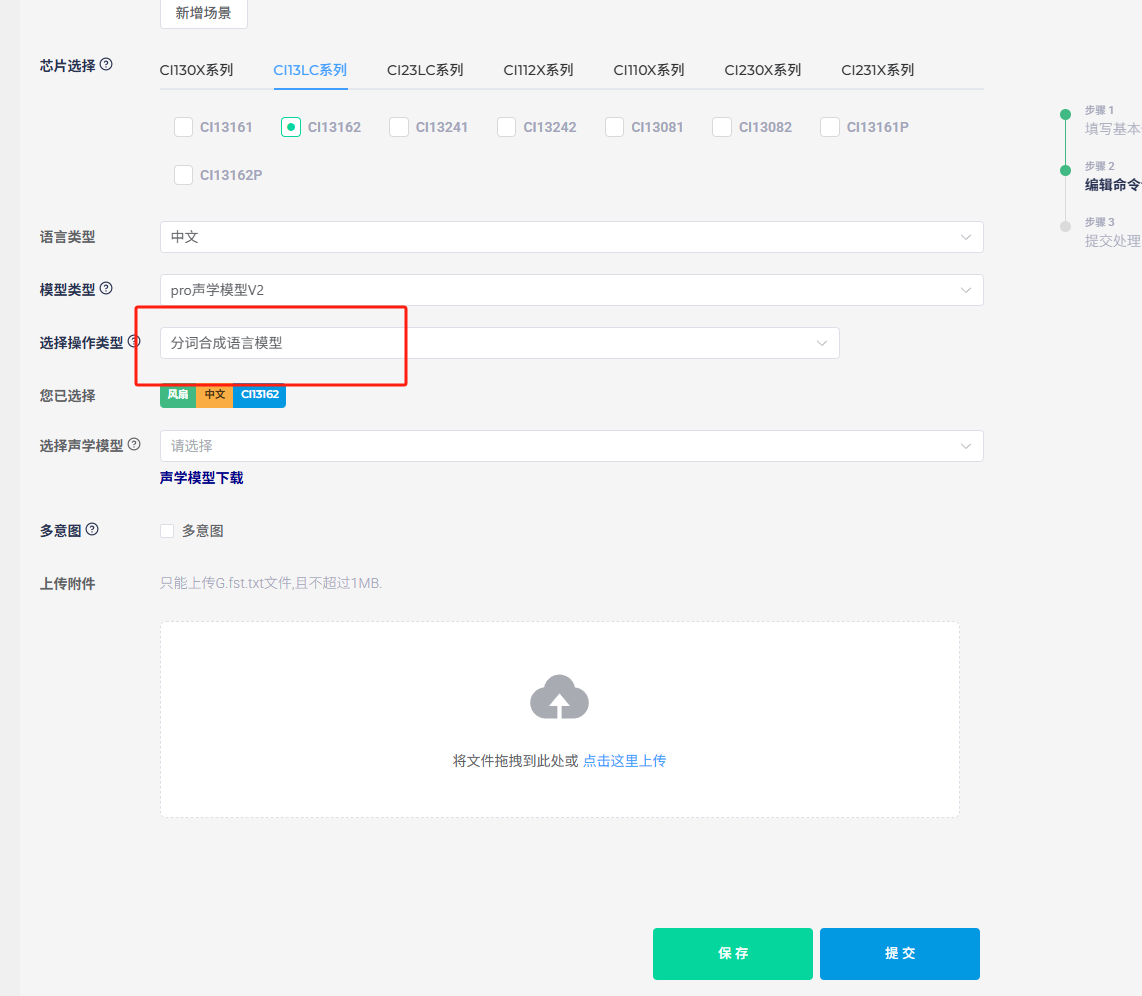
例如四档风容易误识别成十档风,可以在四档风以及相关泛化词的分词后面加一个Tab键隔开(分词格式需要),然后加上0.0的权重数,十档相关分词后面加上0.5的权重数。权重数最低0.0,最高2.0,数字越高权重越低,会降低相应识别灵敏度,十档的权重数初步确认为0.5,可以在平台上模型制作方式选择分词合成模型,重新上传制作模型后测试,观察效果后慢慢调整,调整最小步伐为0.1。
这边也同时可以把四挡风修改为四档风等,在录音时会做各地口音一定程度的兼容,用文字修改为不常用的组词去靠近实际口音可能会导致效果反而不好。效果不好时可以用下面方式增加近音词优化效果。
单个词识别不好优化方式
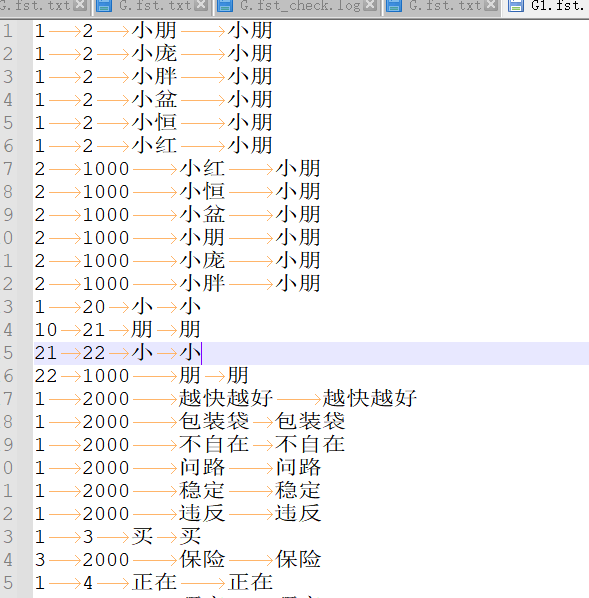
如图,有一个唤醒词叫做”小朋小朋”,因为客户口音以及其他问题,会导致难唤醒,或者作为命令词难识别,此时可以将近似的一些说法加到分词中导向小朋,兼容更多口音效果。
分词中前两列有1、2、3、1000、2000等数字,这些可以认为是识别中间点或者分叉点,例如在识别小朋小朋时会先检测小朋,然后再检测一次小朋,利用两次匹配最终输出正确结果。
数字中1是每个完整命令词或者垃圾词的统一起始点,2、3、4、5是不同的识别节点,用于较长(打开三十六档风可以分为打开、三十六档、风)或者包含相同部分的(打开灯光、打开风扇可以共用打开)命令词的分割,1000是最终命令词的终点,2000是垃圾词的终点,只有最终为1000的词才能有识别输出,最终节点为2000的词用于降低误唤醒或者命令词的误识别,可以加入日常常用的词,一般自动优化时会加入一些,后续客户有反馈误唤醒或误识别较多时可以自己测试或者要一下客户的测试视频,根据体验手动加入。
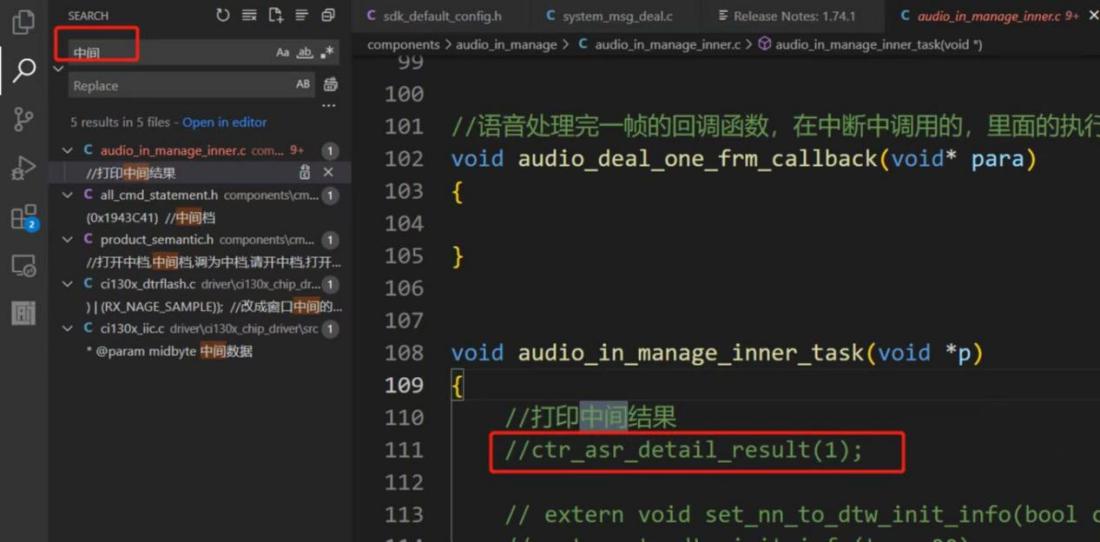
分词优化可以和中间结果打印日志函数结合使用
中间结果打印函数,左上角搜索中间,可以找到相关注释,取消前面的默认注释部分打开输出,日志打印串口就会出现识别时的识别分数和相关的结果词,根据日志打印情况调整分词。
分词上传位置如下图
六. 效果查看与问题分析¶
6.1 效果评估¶
整机体验
最直观的方式就是装到实际的机器中真人体验,根据体验判断是否需要调整。
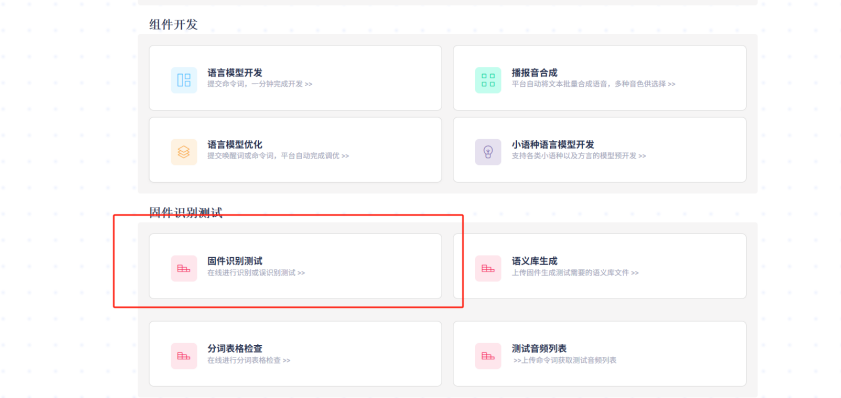
平台固件识别测试
启英泰伦语音AI平台可以通过上传固件和测试音频的方式给出测试结果,用数据分析来给出更加科学的结论。下图为测试入口。
隔音实验室整机测试
结合上述两种方式的测试方式,用整机和音频测试集在专业测试室测试,得出更加贴近实际情况的科学结论。
6.2 常见问题及解决方案¶
| 问题描述 | 可能原因 | 解决方案 |
|---|---|---|
| 唤醒失败 | 1. 环境噪音过大 | 1. 优化声学模型 |
| 2. 麦克风位置不佳 | 2. 调整麦克风位置 | |
| 3. 唤醒词置信度过高 | 3. 降低唤醒词置信度 | |
| 误唤醒频繁 | 1. 唤醒词置信度过低 | 1. 提高唤醒词置信度 |
| 2. 环境噪音干扰 | 2. 增加环境适应性训练 | |
| 3. 模型泛化能力不足 | 3. 优化唤醒词设计 | |
| 命令词识别率低 | 1. 命令词发音相似 | 1. 优化命令词设计 |
| 2. 模型训练不充分 | 2. 优化声学模型 | |
| 3. 背景噪音影响 | 3. 调整麦克风位置 | |
| 系统响应慢 | 1. 算法复杂度高 | 1. 优化算法参数 |
| 2. 系统资源不足 | 2. 减少不必要的功能模块 | |
| 3. 任务调度不合理 | 3. 调整任务优先级 |
6.3 注意事项¶
结构注意事项
主要是麦克风结构位置,可以参考链接产品结构设计确定麦克风安装位置。
测试注意事项
测试中有许多可能影响识别效果的因素,确定结构和安装没问题或者无法改变后,可以根据3.2中下载的模块设计电路压缩包中”硬件调试相关说明文档”文件夹的几个文件来进行硬件、软件、麦克风底噪的排查。