Recognition Performance Test Standard¶
Overview¶
Our company has established enterprise testing standards for speech recognition performance of intelligent voice products. We actively participate in team and industry standards development led by various social organizations. Our speech testing methods and evaluation criteria have gained recognition from the industry and major enterprises. Customers can directly adopt our speech recognition performance testing methods to evaluate the speech recognition capabilities of their developed products.
This document specifies the terminology, definitions, testing specifications (including technical requirements, testing metrics, test items, test content, test equipment, and test environment), testing methods, procedures, as well as test result reporting and traceability for speech module recognition performance testing.
The content of this document is selected from our enterprise standard document Offline ASR Module Recognition Performance Testing Standard, Standard No.: QQYTL001-2018. The descriptions in this document apply to recognition performance testing for all AI offline and offline+online ASR modules.
Terms and Definitions¶
The following terms and definitions are used throughout this document:
1. Artificial Intelligence (AI)
An interdisciplinary field of computer science that develops systems demonstrating human-like intelligence capabilities including reasoning and learning.
2. Automatic Speech Recognition (ASR)
The technological process of converting speech signals into machine-readable text representations.
3. Natural Language Processing (NLP)
The computational techniques for analyzing, understanding and generating human language.
4. Voice Command
A spoken instruction that can be recognized and processed by voice-enabled systems.
5. Artificial Mouth
Also known as simulated mouth: A high-fidelity audio playback device that plays voice commands, replacing human voice as a standardized test sound source.
6. Recognition Rate
The percentage of correctly recognized voice commands out of the total commands tested on the speech module.
7. False Recognition Count
The frequency of incorrect recognitions by the speech module during simulated real-world usage scenarios over a specified time period.
8. False Wake-up
An unintended activation of the wake-up system occurring when: 1. No audio stream is present, or 2. The audio stream lacks wake-up features/events
9. Signal-to-Noise Ratio (SNR)
The power ratio (in decibels) between: - Voice command signal - Ambient noise
10. Residential Environment
The operational setting for voice modules, including: - Bedroom - Living room - Kitchen - Bathroom - Balcony
11. Quiet Environment
Defined as operational environments with ambient noise levels between 25dB-45dB.
12. Moderate Noise Environment
Defined as operational environments with ambient noise levels between 55dB-65dB.
13. High Noise Environment
Defined as operational environments with ambient noise levels between 65dB-80dB.
14. Mechanical Noise in Voice Modules
Noise generated by: 1. Component vibration during operation 2. Friction/impact between mechanical parts 3. Integrated mechanical components in voice recognition systems
Categorized by source: - Aerodynamic noise - Mechanical noise - Electromagnetic noise
15. Background Noise
Noisy background noise refers to the background voice or quasi human voice (such as the noisy voice in the venue and shopping mall environment) or the disturbing sound played by other audio devices other than the voice module, such as the sound from music, news, television and movies.
16. Echo Noise
Echo noise refers to the sound played by the voice module through its own speaker, which interferes with the speech recognition results.
17. Reverberation Noise
The voice received by the voice module after the target speaker’s voice is reflected by a smooth surface (such as a wall or object surface).
18. Environmental Noise
The environment of voice module contains background noise and reverberation, in which the background noise often contains one or more noise sources. For example, the kitchen environment also has the voice of the range hood and cooking; In the bathroom environment, there are wind noise, shower water noise and voice reverberation reflected by smooth walls; The living room environment has voice, TV and other sounds at the same time; The balcony environment has wind noise and outdoor noise (such as vehicle speaker voice, etc.) at the same time; There are engine noise and road noise in the vehicle environment.
19. Test Audio Data
Non training set audio instruction set for speech test.
20. Noise Audio Data
A set of noisy audio for voice testing.
21. Operation
The voice module is in functional operation.
22. Not in Operation
The voice module is not functioning.
23. Voice Prompt Mode
The voice module is actively playing back audio prompts or responses.
24. Non-Voice Prompt Mode
The voice module is in a silent state with No broadcast.
25. Wake-up Words
Special phrases that activate the voice recognition system, allowing it to respond to subsequent commands.
26. Command Words
The complete set of all voice commands recognized by the system, including both wake-up phrases and operational instructions.
27. Microphone Array Configurations
Voice modules can utilize various microphone array configurations:
- By Quantity:
- Dual-microphone array (2 mics)
- Quad-microphone array (4 mics)
- Hex-microphone array (6 mics)
-
Octo-microphone array (8 mics)
-
By Geometry:
- Linear array (microphones in a straight line)
- Circular array (microphones arranged in a circle)
- Planar array (2D microphone arrangement)
28. Intelligent voice Device
Any electronic device that incorporates voice recognition capabilities for user interaction.
Test Specifications¶
Test Categories¶
Recognition/Wake-up Rate Testing¶
- Measures the system’s ability to accurately recognize voice commands and wake words
- Conducted in both quiet (35-45dB) and noisy (55-75dB) environments
- Evaluates performance across different acoustic conditions and distances
False Wake-up Testing¶
- Quantifies unintended activations caused by:
- Non-wake-word speech
- Environmental sounds
- System noise
- Excludes phonetically similar phrases to wake words
- Performed during both active use and idle states
Response Time Testing¶
- Measures latency from command completion to system response
- Tests conducted at various distances and noise levels
- Includes both initial wake-up and subsequent command processing
System Stability Testing¶
- Long-duration testing under continuous operation
- Performance monitoring across temperature variations
- Assessment of memory usage and resource management
Test Environment Requirements¶
Testing environments are designed to simulate real-world conditions where voice-enabled devices operate. Each environment is characterized by specific acoustic properties that affect speech recognition performance.
| Environment | application scenario | ambient noise (dB) | reverberation (s) | minimum distance (m) | maximum distance (m) | reference area of application scenario (m2) | applicable voice equipment |
|---|---|---|---|---|---|---|---|
| Quiet environment | unlimited | 35-45 | 0.45-0.55 | 1 | 5 | 15-35 | All voice recognition devices |
| Working condition environment | kitchen | 55-60 | 0.65-0.75 | 1 | 2 | 5-10 | kitchen voice recognition equipment (such as microwave oven, range hood, rice cooker, etc.) |
| Working condition environment | Toilet | 55-60 | 0.65-0.75 | 1 | 2 | 5-10 | Bathroom voice recognition equipment (such as bathtub, air heater, toilet, etc.) |
| Working environment | balcony | 55-60 | NA | 1 | 2 | 5-10 | balcony voice recognition equipment (such as washing machine, clothes dryer, balcony lamp, etc.) |
| Working condition environment | living room (hall) | 55-60 | 0.45-0.55 | 1 | 5 | 15-35 | living room speech recognition equipment (such as air conditioner, central control, remote controller, tea set, oxygen generator, living room lamp, TV, etc.) |
| Working environment | bedroom | 55-60 | 0.45-0.55 | 1 | 5 | 10-20 | bedroom voice recognition equipment (such as air conditioner, remote controller, desk lamp, TV, etc.) |
| Working condition environment | Strong noise | 65-75 | NA | 0.5 | 2 | 5-10 | Strong noise equipment or environment (such as when the fan is working at high wind damper) |
Note: For devices with audio playback capabilities (e.g., smart speakers), additional testing is required during active media playback to ensure reliable voice recognition performance.
Note: The reference area of the application scenario in Table 1 conforms to the specifications for the space area of the kitchen, toilet, balcony, living room (hall) and bedroom suite in the “Five Sets of Interior Space” in GB50096-2011 Code for Residential Design.
Microphone Configuration Requirements¶
Supported Configurations¶
Voice modules support various microphone configurations to accommodate different product requirements:
-
Single Microphone - Basic configuration for cost-sensitive applications - Limited noise cancellation capabilities - Ideal for close-range voice capture
-
Microphone Arrays - Multiple microphones arranged in specific geometric patterns - Enables advanced beamforming and noise reduction - Supports far-field voice capture - Minimum 10mm spacing between adjacent microphones required
Reference Configurations¶
Single Microphone Setup¶
Dual-Microphone Array¶
Test Language Requirements¶
The voice commands for the test shall be in the standard official language, and the Chinese language shall be Putonghua Grade II, Grade B and above.
Test Speech Speed Requirements¶
Normal speaking speed, 150-180 words/minute for Chinese mandarin.
Speech Recognition Rate/Wake-up Rate Test Index¶
| Test Item | Environment | Working Status of Voice Equipment | Signal-to-Noise Situation | Noise Set | Test Set | Index | Applicability Description |
|---|---|---|---|---|---|---|---|
| Local recognition rate/ Wake up rate test |
Quiet environment | Non operating/Non broadcasting | Voice: 60dB~70dB Noise: 35dB~45dB |
NA | Wake up word set instruction word set | Minimum distance: ≥ 97% Maximum distance: ≥ 95% |
Applicable to all speech recognition equipment |
| Local recognition rate/ Wake up rate test |
Working condition environment | Operation | Voice: 65dB~75dB Noise: 55~60dB |
Environmental noise+mechanical noise of voice equipment | Wake up word set instruction word set | Minimum distance: ≥ 92% Maximum distance: ≥ 85% |
Applicable to voice recognition equipment that can generate mechanical noise |
| Local recognition rate/ Wake up rate test |
Operating environment | Non operating/Non broadcasting | Voice: 65dB~75dB Noise: 55~60dB |
Environmental noise | Wake up word set command word set | Minimum distance: ≥ 92% Maximum distance: ≥ 88% |
Applicable to voice recognition equipment with medium or higher ambient noise under operating conditions |
| Local recognition rate/ Wake up rate test |
Working condition environment | Broadcast | Voice: 65dB~75dB Noise: 55~60dB |
Ambient noise+Echo noise | Wake up word set instruction word set | Minimum distance: ≥ 92% Maximum distance: ≥ 85% |
Voice recognition equipment suitable for long broadcast and audio playback |
| Local recognition rate/ Wake up rate test |
Working condition environment | Operation (strong noise) | Voice: 65dB~75dB |
Note:
- The minimum distance, according to the “environment”, “application scenario” refers to “Table 1” to determine the specific distance.
- The maximum distance is determined according to the “environment”, and the “application scenario” refers to “Table 1”.
- The noise of voice equipment (such as kitchenhood) that generates strong mechanical noise will reach 75± 5dB.
False Wake-up Test Index¶
| Test Item | Noise Set | Indicator | Description of False Wakeup Noise Set |
|---|---|---|---|
| False wake-up test | False wake-up noise set | <=3 times/24H | 1) False wake-up noise set: a 24-hour noise corpus including: 4-hour TV noise set (with voice) +4-hour music (pure music or songs) +8-hour environmental noise set (where the equipment is located) +8-hour quiet environment 2) There is no wake-up word voice in the false wake-up noise set, and the noise decibel is 55dB - 65dB. |
Response Time Test Index¶
Response time: The duration between the moment a voice command is played by the artificial mouth at close range (less than 50 cm) and the moment the voice recognition module delivers the recognized command to the device’s control or communication interface. The response time should be less than 1.0 second.
Stability Test Index¶
The recognition stability test of speech recognition module in wake-up and non wake-up states under ambient noise.
Recognition stability test under wake-up state: Play wake-up words every 1 second, run for 72 hours, no crash or restart, and can identify normally.
Recognition stability test under non wake-up state: every T_wakeup_time, wake-up words are played, 72 hours test, without crash or restart, and can be recognized normally.
T_wakeup_time is equal to the time from wake-up to exiting wake-up state plus 1 second.
Audio Collection and Standardization for Test¶
Wake Word Audio Collection Recording The wake word set includes wake words and command words that can be directly controlled without a wake word. Five males and five females, totaling 10 adult speakers, read the wake word set, which was recorded using high-fidelity recording equipment. The speech sampling rate is 44.1kHz, with environmental noise <30dB, reverberation <0.3s, and speakers positioned 20-30cm from the microphone. There is a 2-3 second pause between words, and the reading is done in the standard official language. For Mandarin Chinese, the standard requirement is Level 2B or above, with a speaking speed of 150-180 characters per minute.
Command Word Audio Collection Recording This includes wake words and all other command words. Five males and five females, totaling 10 adult speakers, read the wake word set, which was recorded using high-fidelity recording equipment. The speech sampling rate is 44.1kHz, with environmental noise <30dB, reverberation <0.3s, and speakers positioned 20-30cm from the microphone. There is a 2-3 second pause between words, and the reading is done in the standard official language. For Mandarin Chinese, the standard requirement is Level 2B or above, with a speaking speed of 150-180 characters per minute.
Test Equipment and Instrumentation¶
Test Equipment Specifications¶
The following equipment is required for comprehensive speech recognition testing. Equivalent models with similar specifications may be substituted with prior approval.
| S/N | Category | Equipment | Equipment Model | Equipment Brand | Function |
|---|---|---|---|---|---|
| 01 | Computer | Desktop/laptop | Unlimited | Unlimited | Monitor whether the voice module feedback accurately outputs the test results |
| 02 | Sound source | Artificial mouth | 4227-A | Brüel&Kjær | Play audio signal |
| 03 | Noise monitoring | Precision noise meter (sound level meter) | 1357 | TES | Test the sound pressure reaching the microphone |
| 04 | Noise source | Speaker/TV | Recommended model of monitor speaker: FX8 | Fluid Audio | Play noise and simulate external interference |
| 05 | Audio Collection | High Fidelity Recording Equipment | R44 | Roland | Audio Recording |
Table 4 Speech Recognition Test Equipment
Artificial Mouth¶
Model: 4227-A
Performance index:
-
Rated output sound pressure SPL:
-
200Hz - 2kHz ----- 110dB
- 100Hz - 8kHz ----- 100dB *Distortion (@ 94dB):
- 200Hz - 250Hz ----- <2%
- ’>‘250Hz ----- <1% *Impedance ------ 4 Ω *Maximum bearing ----- 10W *Instantaneous withstand power ----- 50W *Nozzle diameter ----- 20mm
High-precision Noise Meter¶
Model: TES 1357
Performance index:
- 0.1dB resolution;
- The measuring range is 30 to 130dB;
- 1/1,⅓,⅙,1/12,1/24 octave spectrum analysis software (optional);
- Accuracy± 1.5dB (ref 94dB @ 1KHz);
- Weighted measuring range: 30dB to 130dB;
- C-weighted measuring range: 35dB~130dB;
- Measuring gear 30-80dB, 50-100dB, 60-110dB, 80-130dB;
- Frequency response 31.5 Hz to 8KHz;
- Digital display 4-digit LCD, 0.1dB resolution, updated every 0.5s;
- AC/DC signal output 2Vrms/full scale of each gear, 10mV/dB.
Noise Source: Monitoring Speaker¶
Model: Fluid Audio FX8
Performance index:
- Frequency response: 35Hz - 22kHz (± 3dB);
- Cross frequency: 2.4kHz;
- Low frequency amplifier power: 80 watts;
- High frequency amplifier power: 50 watts;
- Signal noise:>100dB (typical A-weighted);
- Polarity: positive signal+input generates an outward low-frequency displacement;
- Input impedance: 20 kΩ (balanced type), 10 kΩ (unbalanced type);
- Input sensitivity: when the volume control is set to the maximum value (102dB of maximum sound pressure), the input of 85 mV pink noise will produce an output sound pressure of 95dBA;
- Power supply: 115V~50/60 Hz or 230V~50/60 Hz (user can switch);
- Protection device: RF interference, output current limitation, over temperature protection, transient on/off;
- Protection, subwoofer filter, external power fuse;
- Box: medium density fiberboard with ethylene base;
- Size (single monitor speaker): 340mm (height) x254mm (width) x270mm (length);
- Weight (single monitor speaker): 9.8kg.
Speech Recognition Test Environment¶
As shown in the figure below, the artificial mouth (sound source) is directly in front of the microphone of the voice module, with a horizontal linear distance of L meters. The artificial mouth (sound source) is 120 - 150cm from the ground; The noise source (monitor speaker/TV), voice module and precision noise meter are located at the same plane (80 - 100cm from the ground); The distance between the noise source (monitor speaker/TV) and the microphone of the voice module is ≥ 150cm, and the precision noise meter and the microphone of the voice module are as close as possible (the distance between the two is ≤ 5cm), but cannot contact the microphone of the voice module.
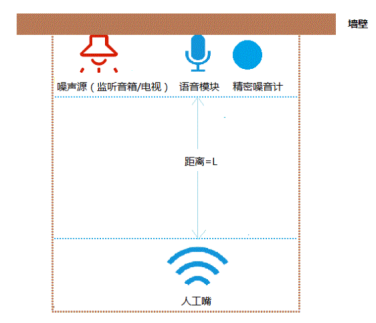
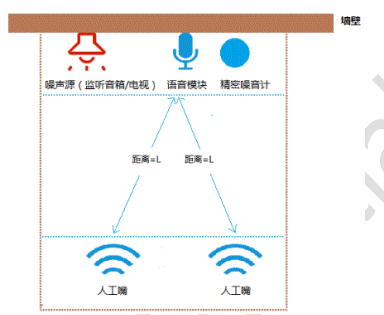
Note:
- Front: the position and angle of the artificial mouth can be determined according to the actual scene of the customer;
- L: It depends on the actual scene;
- Noise source: It can be broadcast by monitoring the speaker or TV. The location and angle of the noise source can be determined according to the actual situation of the customer.
Recognition Rate/Wake-up Rate Test Methods and Steps¶
According to the test requirements, change the position and angle of the mouth from the voice module to build different acoustic scenes. The noise source (monitor speaker/TV) plays the noise set, the mouth plays the corresponding test set, and records the test data.
Calculation Method:
- Recognition rate=(number of correctly recognized instructions/total number of input instructions) * 100%
- Wake up rate=(times of correct wake-up rate/total number of input instructions) * 100%
Step:
- Use the noise source (monitor speaker/TV) to continuously broadcast the noise set; The manual mouth plays the commands in the test set one by one at a certain time interval;
- Record test data;
- Statistics and calculation of test results.
False Wake-up¶
According to the requirements of the test indicators, change the position and angle of the artificial mouth from the voice module to build different acoustic scenes. The noise source (monitor speaker/TV) plays the noise set, the artificial mouth plays the corresponding test set, and counts the number of false wakeups.
Step:
- Use the noise source (monitor speaker/TV) to continuously broadcast the noise set, and use the artificial mouth to broadcast the test set;
- Count the number of false wakeups.
Response Time¶
Set up the test environment, open the voice recording tool, and play the test set. After the broadcast, use the voice recording tool to calculate the time interval between the voice command and the broadcast as the response time.
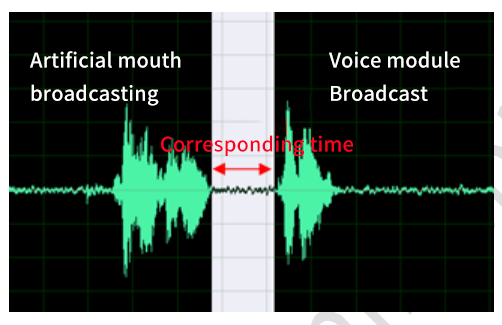
Step:
- Use artificial mouth to play test set;
- Record test data;
- Calculate the response time.
Recognition Stability¶
Set up the test environment, the noise source (monitor speaker/TV) plays different kinds of noise, the artificial mouth plays the test set, the test voice module group runs normally for 168 h, no restart record, and the response time is less than 1.0 s.
Step:
- Use artificial mouth to play test set;
- Record the test data.
Note: As a reference standard and method for testing general speech recognition equipment, this document can be adjusted according to actual application scenarios and conditions. If there is no artificial mouth, you can also speak in an artificial way. If you need to analyze the test results, you can use high fidelity recording equipment or mobile phones and other recording equipment to record the test environment for speech recognition and optimization
Appendix¶
| Speech recognition equipment | corresponding mechanical noise of speech equipment | corresponding environmental noise |
|---|---|---|
| Range hood | Range hood in operation noise | Kitchen ambient noise |
| Dishwasher | Dishwasher in operation noise | Kitchen ambient noise |
| Rice cooker | None | Kitchen environment noise |
| Microwave oven | Microwave oven in operation noise | Kitchen ambient noise |
| Soymilk maker | Soymilk maker in operation noise | Kitchen environment noise |
| Coffee maker | Coffee maker in operation noise | Kitchen ambient noise |
| Refrigerator | Refrigerator in operation noise | Kitchen ambient noise |
| Air conditioner | Air conditioner in operation noise | Living room ambient noise |
| Electric fan | Electric fan in operation noise | Living room ambient noise |
| Vacuum cleaner | Vacuum cleaner in operation noise | Living room ambient noise |
| Humidifier | None | Ambient noise in living room |
Note: The noise can be collected according to the actual application scenario of the terminal equipment