Automatic Speech Recognition(ASR) Principles¶
The principle of ASR is converting voice sequences into text sequences. The common system framework is as follows:

This document introduces relevant technologies in ASR. To facilitate understanding, it first covers voice front-end signal processing, then explains the basic principles of ASR, followed by descriptions of acoustic and language models.
1. Voice Front-end Signal Processing¶
Voice front-end signal processing involves processing raw voice signals to better represent the essential features of speech. The relevant techniques are outlined in the table below:
1.1 Voice Activity Detection (VAD)¶
VAD detects the start of a voice signal, separating speech segments from non-speech (silence or noise) segments. VAD algorithms are categorized into three types: threshold-based VAD, classifier-based VAD, and model-based VAD.
-
Threshold-based VAD extracts time-domain (short-term energy, zero-crossing rate, etc.) or frequency-domain (MFCC, spectral entropy, etc.) features and uses thresholds to distinguish between speech and non-speech.
-
Classifier-based VAD treats voice activity detection as a binary classification (speech and non-speech) problem, using machine learning to train classifiers for detection.
-
Model-based VAD constructs a complete speech recognition model to differentiate speech from non-speech segments. Due to real-time requirements, it is not widely applied.
1.2 Noise Reduction¶
In everyday environments, various noises from operating devices exist, such as noise from air conditioners and fans. Noise reduction algorithms aim to reduce environmental noise, improve the signal-to-noise ratio, and enhance recognition performance.
Common noise reduction algorithms include adaptive LMS (Least Mean Squares) and Wiener filtering.
1.3 Acoustic Echo Cancellation (AEC)¶
Echo occurs in duplex mode when a microphone picks up signals from a speaker, such as when controlling a device with voice while it plays music.
Acoustic Echo cancellation is usually achieved by using adaptive filter, that is, designing a filter with adjustable parameters, adjusting the filter parameters through adaptive algorithms (LMS, NLMS, etc.), simulating the channel environment of echo generation, and then estimating the echo signal for cancellation.
1.4 Reverberation Cancellation¶
Voice signals collected by microphones after multiple indoor reflections result in reverberant signals that can cause masking effects, severely degrading recognition rates. Front-end processing is necessary in this case.
Reverberation cancellation methods mainly include inverse filtering-based method, beamforming-based method and deep learning-based method.
1.5 Sound Source Localization¶
Microphone arrays are widely used in speech recognition. Sound source localization is a primary task of array signal processing. Using microphone arrays to determine speaker positions is to prepare for beamforming in the recognition stage.
Common algorithms for sound source localization include high-resolution spectral estimation (e.g., MUSIC algorithm), time difference of arrival (TDOA) algorithms, and minimum variance distortionless response (MVDR) beamforming algorithms.
1.6 Beamforming¶
Beamforming is a method of forming spatial directivity by processing (such as weighting, time delay, summation, etc.) The output signals of each microphone of a microphone array arranged in a certain geometric structure, which can be used for sound source localization and reverberation cancellation.
Beamforming is categorized into fixed beamforming, adaptive beamforming, and post-filter beamforming.
2. Basic Principles of Automatic Speech Recognition(ASR)¶
Automatic Speech Recognition is to convert a speech signal into corresponding text information. The system mainly consists of four parts: feature extraction, acoustic model, language model, dictionary and decoding. In order to extract the features more effectively, it is often necessary to filter and frame the collected sound signal to extract the signal to be analyzed from the original signal; After that, the feature extraction work converts the sound signal from the time domain to the frequency domain, and provides appropriate feature vectors for the acoustic model; in the acoustic model, the score of each feature vector on the acoustic features is calculated according to the acoustic characteristics; and in the language model, the probability of the sound signal corresponding to a possible phrase sequence is calculated according to a theory related to linguistics; Finally, according to the existing dictionary, the phrase sequence is decoded to obtain the final possible text representation. The relationship between the acoustic model and the language model is expressed by the Bayesian formula as follows:
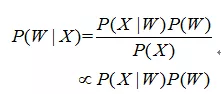
Where P(X|W) is the acoustic model, and P(W) is the language model. Most research separates acoustic and language models, with differences in acoustic models distinguishing various manufacturers’ systems. Additionally, end-to-end (Seq-to-Seq) methods based on big data and deep learning are evolving, directly computing P(X|W), treating acoustic and language models as a whole.
3. Traditional HMM Acoustic Model¶
The acoustic model links observed features of voice signals with speech modeling units of sentences, calculating P(X|W). Hidden Markov Models (HMM) are commonly used to address the indefinite length relationship between speech and text, as shown in the HMM diagram below.

The acoustic model is represented as:
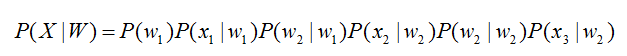
Among, The initial state probability P(w1) and the state transition probabilities (P(w2|w1)、P(w2|w2)) can be calculated by a conventional statistical method, The transmission probabilities (P(x1|w1)、P(wx2|w2)、P(x3|w2)) can be solved by Gaussian mixture model GMM or deep neural network DNN.
Traditional systems commonly use GMM-HMM acoustic models, as illustrated below:
Where awiwj denotes the state transition probability P(wj|wi), The speech features are represented as X=[x1,x2,x3,…], and the relationship between the features and the States is established through the Gaussian mixture model GMM. Thus, the emission probability P(xj|wi) is obtained, and different wi States correspond to different parameters of the Gaussian mixture model.
Speech recognition based on GMM-HMM can only learn the shallow features of speech, but cannot obtain the high-order correlation between data features. DNN-HMM can improve the recognition performance by using the strong learning ability of DNN. The schematic diagram of its acoustic model is as follows:

The difference between GMM-HMM and DNN-HMM is that DNN is used to replace GMM to solve the transmission probability P(xj|wi), and the advantage of GMM-HMM model is that the calculation amount is small and the effect is not bad. DNN-HMM model improves the recognition rate, but it requires high computing power of hardware. Therefore, the selection of the model can be adjusted according to the actual application.
4. Seq-to-Seq model¶
Speech recognition can actually be seen as a problem of switching between two sequences. The actual goal of speech recognition is to transcribe an input audio sequence into a corresponding text sequence. The audio sequence can be described as O = O1, O2, O3.., ot, where oi represents the speech features of each frame and t represents the time step of the audio sequence (usually, each second of speech is divided into 100 frames. Each frame can extract 39-dimensional or 120-dimensional features.) Similarly, the text sequence can be described as W = w1, W2, W3.., wt, where n represents the number of corresponding words in the speech (not necessarily words, but also other modeling units such as phonemes). It follows that the speech recognition problem can be modeled by a sequence-to-sequence model. The traditional speech recognition problem is a hybrid structure of DNN-HMM, and it also needs multiple components such as language model, pronunciation dictionary and decoder to model together. The construction of the pronunciation dictionary requires a lot of expert knowledge, and multiple model components need to be trained separately, so they can not be optimized jointly. Seq2Seq model provides a new solution for speech recognition modeling. Applying Seq2Seq model to speech recognition problems has many obvious advantages: end-to-end joint optimization, completely getting rid of Markov assumption, and no need for pronunciation dictionary.
5. CTC¶
In speech recognition, there are usually speech segments and corresponding text labels, but we do not know the specific alignment relationship, that is, the alignment between characters and speech frames, which brings difficulties to speech recognition training tasks; CTC does not care about the specific and unique alignment relationship when training, but considers the probability sum of all possible sequences corresponding to labels, so it is more suitable for this type of recognition task. CTC decodes synchronously with the acoustic feature sequence, that is, every time a feature is input, a label is output, so its input and output sequence lengths are the same. But we said earlier that the length of input and output is obviously very different, so a blank symbol is introduced in CTC, and the text sequence with blank is called an alignment result of CTC. After getting the alignment, first de-duplicate the symbol, then delete the blank, and then restore the text of the annotation.

6. RNN Transducer¶
CTC has brought great benefits to the acoustic modeling of speech recognition, but there are still many problems in CTC models, the most significant of which is that CTC assumes that the outputs of the model are conditionally independent. There is a certain degree of deviation between this basic assumption and the speech recognition task. In addition, the CTC model does not have the ability of language modeling, and it does not really achieve end-to-end joint optimization. RNN-T is no longer a structure with one input corresponding to one output, but enables it to generate multiple token outputs for one input until one null character is output to indicate that the next input is required, that is to say, the final
number must be the same as the length of the input. Because each frame of input must generate one
.

7. Language Model¶
The language model is related to text processing. For example, we use the intelligent input method. When we input “你好”, the suggested words of the input will appear “你好” instead of “尼毫”. The suggested words are arranged according to the order of the language model score.
The language model in speech recognition is also used to process the word sequence, which combines the output of the acoustic model and gives the word sequence with the maximum probability as the result of speech recognition. Because the language model represents the probability of occurrence of a sequence of words, it is generally represented by the chain rule, for example, W is composed of w1,w2,…wn, then P (W) can be expressed by the conditional probability correlation formula:

Long conditions make probability estimation difficult. A common approach assumes each word’s probability distribution depends only on a few preceding words, forming an n-gram model. In n-gram models, each word’s probability distribution depends on the preceding n-1 words. For example, in a trigram (n=3) model, the formula simplifies to:
