Instructions for speech noise reduction¶
The DENOISE algorithm can effectively suppress the stationary noise, and has a good noise suppression effect while ensuring the degree of speech distortion. After this function is enabled, the recognition effect can be improved by reducing the steady-state noise, but at the same time, this function will consume 24KB of chip internal storage space and CPU bandwidth resources. This document mainly introduces the applicable scenarios of the noise reduction algorithm and how to open the function.
1. Speech noise reduction algorithm¶
-
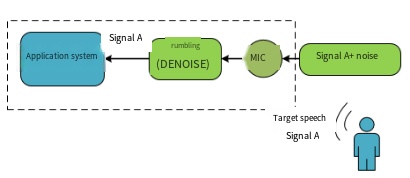
The block diagram of the application principle of the speech noise reduction algorithm is as follows. The human voice is the target speech signal A. The noise and signal A enter the chip after complex mixing in the application environment. The speech noise reduction algorithm can suppress the noise signal and improve the signal-to-noise ratio of signal A, thereby improving the recognition effect.
-
At present, the speech noise reduction algorithm provided by Chipintelli is only applicable to stationary noise and semi-stationary noise.
2. Voice noise reduction algorithm software configuration method¶
The user can open the ci _ ssp _ config. C file in the SDK package, and the voice noise reduction algorithm has the following parameters for the user to debug:
denoise_config_t denoise_config =
{
.start_Hz = 0, //降噪起始频率 单位Hz
.end_Hz = 8000, //降噪结束频率 单位Hz
.fre_resolution = 31.25f, //频率分辨率 单位Hz :16000/256
.aggr_mode = 1, //算法处理的效果等级:0,1,2,处理效果依次增强,失真也会变大
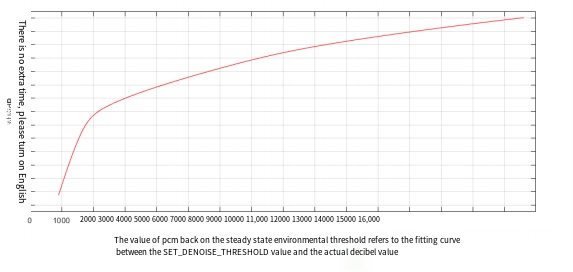
.set_denoise_threshold = 3200, //默认帧平均幅值>=3200起效
.set_denoise_thr_window_size = 20 //门限判断窗长
};
3. Speech Noise Reduction Algorithm Software Debugging Instruction¶
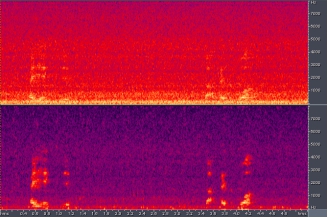
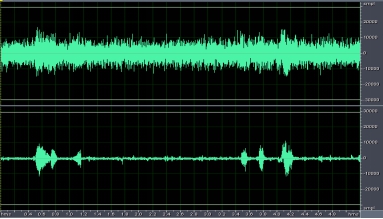
- The following figure shows the comparison effect of the time-domain signal after real-time processing. It can be seen from the figure that the original left channel data (upper half) is a mixture of target speech and noise. After being processed by the speech noise reduction algorithm, the noise is suppressed and the signal-to-noise ratio of the target speech is improved (lower half).
- Below is a frequency domain display of the same audio. This is a normal result.